
This influx of technology has sparked a fierce debate about its potential benefits and dangers, raising important questions about the future of development and the role of humans in it.
Major players in the tech industry, including American Big Tech companies, have found themselves in a competitive "gold rush," each rushing to create their versions of language learning models (LLMs). Microsoft has responded with Bing, and Google has introduced Bard, among others. These alternatives to OpenAI's ChatGPT are a testament to the recognized potential of AI in streamlining the coding process and improving developer productivity.
Yet, as promising as these new technologies may be, they are not without their limitations and challenges. One of the most significant concerns is the fact that these LLMs primarily offer assistance in mainstream languages, leaving those working with newer programming languages or emerging technologies somewhat in the lurch. Additionally, the fact that the knowledge base of these tools is somewhat outdated raises further questions about their applicability and effectiveness.
These tools' ability to assist with routine developer tasks such as research, writing both simple and complex code, debugging, and documentation is a topic of ongoing exploration and discussion. As we delve into the specifics of how these LLMs perform in these areas, we also need to address the broader question: How can we leverage the advantages of these tools while also mitigating their limitations and potential dangers? This article aims to explore these topics, providing insights into the current landscape of AI tools in development and the potential pathways for their future evolution.
Use case 1: Research
When developers engage in research during the development process, they often seek information and resources to enhance their understanding, make informed decisions, and solve problems. Some of the areas typically researched are the following:
-
Programming languages, frameworks, and updates.
-
APIs, libraries, and usage examples.
-
Algorithms, data structures, and optimization techniques.
-
Design patterns and architectural principles.
-
Performance optimization methodologies.
-
Security, vulnerabilities, and best practices.
-
Emerging technologies, tools, and trends.
-
Error messages, exception handling, and debugging.
We cannot go point-by-point in this article, so let’s focus on two topics: programming languages and best practices.
OpenAI’s ChatGPT: Base benchmark
As a developer, you might come across the following question: “How can I do X in a programming language Y, and how can I make it idiomatic.” Since the internet is filled with Hello World examples, let’s talk about something a bit more complex.
Assuming I’m building my version of the “ping” program, a bit more simplified than the original, let’s say I’m trying to research its implementation in two programming languages: Python and Go.
So, what do we want to achieve? I would like to ping an IP address (hardcoded as a string) 15 times and obtain all relevant information: ICMP sequence number, TTL (Time-To-Live), and RTT (Return-Trip-Time), as well as produce statistics in the end (success rate, and RTT minimum/maximum/average/standard deviation).
import re
import statistics
import subprocess
def ping_ip_address(ip_address, count=15):
# Prepare the command
command = f"ping -c {count} {ip_address}"
# Execute the command
process = subprocess.Popen(command, shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
output, _ = process.communicate()
# Parse the output
lines = output.decode().split('\n')
pattern = r"icmp_seq=(\d+) ttl=(\d+) time=([\d.]+) ms"
results = []
for line in lines:
match = re.search(pattern, line)
if match:
icmp_seq = int(match.group(1))
ttl = int(match.group(2))
rtt = float(match.group(3))
results.append((icmp_seq, ttl, rtt))
# Calculate statistics
success_rate = len(results) / count * 100
rtts = [result[2] for result in results]
rtt_min = min(rtts)
rtt_max = max(rtts)
rtt_avg = statistics.mean(rtts)
rtt_stddev = statistics.stdev(rtts)
# Return the results and statistics
return results, success_rate, rtt_min, rtt_max, rtt_avg, rtt_stddev
# Usage example
ip_address = "8.8.8.8" # IP address to ping
ping_count = 15 # Number of pings
results, success_rate, rtt_min, rtt_max, rtt_avg, rtt_stddev = ping_ip_address(ip_address, count=ping_count)
# Display the results
for icmp_seq, ttl, rtt in results:
print(f"ICMP sequence: {icmp_seq}, TTL: {ttl}, RTT: {rtt} ms")
print(f"\nSuccess rate: {success_rate:.2f}%")
print(f"RTT - Min: {rtt_min} ms, Max: {rtt_max} ms, Average: {rtt_avg:.2f} ms, StdDev: {rtt_stddev:.2f} ms")This code surprisingly worked pretty well and produced the following output:

Likewise, in Go, the implementation produces desired results. Sadly due to the source code being a bit too long to post, I will only attach results.

Google Bard and Microsoft Edge Bing AI
Here’s where things get pretty interesting. The image above shows that Google Bard’s code contains an exception (missing import), while Bing managed to produce a working example.

Conclusion
From my experiences, it seems that both ChatGPT and Microsoft's Bing AI have demonstrated proficiency in generating code in response to specific prompts, while Google's Bard has shown some limitations in this regard. This comparison reveals some critical points about the current landscape of AI tools for development.
In terms of coding assistance, AI's ability to generate working code from specific prompts is an invaluable asset to developers. It's clear from provided examples that ChatGPT and Bing AI are both capable of generating Python and Go code that performs the desired task of pinging an IP address multiple times and producing relevant statistics.
The error message from Bard's Python code suggests a lack of awareness about the need for specific library imports, in this case, the 're' library for regex operations. This could potentially indicate the model's limitations in understanding the dependencies of the code it generates, which is a crucial factor for practical use.
The discrepancy in the Go code generation is also telling. Syntactic errors in the generated code indicate a lack of understanding of the language's syntax or failure to correctly apply it. This could be a result of several factors, such as insufficient training data in the specific language or limitations in the model's language generation capabilities.
My research task comparison brings to light another important aspect of these tools: their data cutoff. ChatGPT's training data being cut off in 2021 may limit its knowledge of developments beyond that point. However, the incorporation of web browsing capabilities in the premium version helps to mitigate this limitation by allowing access to more recent information.
In comparison, Bing AI's access is tied to the Microsoft Edge browser, and its limited query count could be seen as a disadvantage, as it adds an extra step for users and potentially restricts their usage.
Finally, from a user perspective, usability and price are significant factors in choosing a tool. ChatGPT's win in these categories, coupled with its code generation capabilities, makes it a strong contender in the market. While it shares accuracy with Bing AI, other factors could tip the balance in its favor for many users.
Use case 2: Simple algorithms
One of the simple algorithms you might come across is the A* search algorithm. In my quest to learn which AI is best at the job, I’ve decided to ask them to implement it + benchmark it for performance themselves. This time in TypeScript, to keep things interesting.
This experiment provided a fascinating look into the current capabilities and limitations of AI models in code generation and problem-solving tasks. The request for an implementation of the A* search algorithm in TypeScript was a robust test, requiring not just an understanding of coding syntax but also a grasp of more complex algorithmic concepts.
The results reveal several interesting points:
Firstly, ChatGPT was the only model that was able to produce working TypeScript code, showcasing its ability to generate complex, functional code that adheres to a specific programming language's syntax. This is a significant strength, especially when compared with the performance of Bing and Bard. Bing's refusal to write code, despite having done so recently, is an interesting behavior. It could suggest a lack of consistency or perhaps a limitation in its handling of complex algorithmic tasks.
class NodeModel {
public x: number;
public y: number;
public g: number;
public h: number;
public f: number;
public parent: NodeModel | null;
constructor(x: number, y: number) {
this.x = x;
this.y = y;
this.g = 0;
this.h = 0;
this.f = 0;
this.parent = null;
}
calculateHeuristic(target: NodeModel) {
// Manhattan distance heuristic
this.h = Math.abs(this.x - target.x) + Math.abs(this.y - target.y);
}
}
function astarSearch(
start: NodeModel,
target: NodeModel,
grid: NodeModel[][]
): NodeModel[] | null {
const openList: NodeModel[] = [];
const closedList: NodeModel[] = [];
openList.push(start);
while (openList.length > 0) {
// Find NodeModel with the lowest f cost in the open list
let currentNodeModelIndex = 0;
for (let i = 0; i < openList.length; i++) {
if (openList[i].f < openList[currentNodeModelIndex].f) {
currentNodeModelIndex = i;
}
}
const currentNodeModel = openList[currentNodeModelIndex];
// Move the current NodeModel from the open list to the closed list
openList.splice(currentNodeModelIndex, 1);
closedList.push(currentNodeModel);
// Found the target NodeModel, reconstruct and return the path
if (currentNodeModel === target) {
const path: NodeModel[] = [];
let current = currentNodeModel;
while (current !== null) {
path.push(current);
current = current.parent!;
}
return path.reverse();
}
// Generate neighbors
const neighbors: NodeModel[] = [];
const { x, y } = currentNodeModel;
if (x > 0 && grid[x - 1][y] !== null) {
neighbors.push(grid[x - 1][y]);
}
if (x < grid.length - 1 && grid[x + 1][y] !== null) {
neighbors.push(grid[x + 1][y]);
}
if (y > 0 && grid[x][y - 1] !== null) {
neighbors.push(grid[x][y - 1]);
}
if (y < grid[0].length - 1 && grid[x][y + 1] !== null) {
neighbors.push(grid[x][y + 1]);
}
for (const neighbor of neighbors) {
if (closedList.includes(neighbor)) {
continue;
}
const gScore = currentNodeModel.g + 1;
if (!openList.includes(neighbor) || gScore < neighbor.g) {
neighbor.g = gScore;
neighbor.calculateHeuristic(target);
neighbor.f = neighbor.g + neighbor.h;
neighbor.parent = currentNodeModel;
if (!openList.includes(neighbor)) {
openList.push(neighbor);
}
}
}
}
// No path found
return null;
}
// Benchmark function
function benchmarkAStar(gridSize: number) {
const grid: NodeModel[][] = [];
// Generate a grid of NodeModels
for (let i = 0; i < gridSize; i++) {
const row: NodeModel[] = [];
for (let j = 0; j < gridSize; j++) {
row.push(new NodeModel(i, j));
}
grid.push(row);
}
const start = grid[0][0];
const target = grid[gridSize - 1][gridSize - 1];
// Start the benchmark timer
console.time("A* Search");
// Run A* search algorithm
const path = astarSearch(start, target, grid);
// Stop the benchmark timer
console.timeEnd("A* Search");
if (path !== null) {
console.log("Path found!");
} else {
console.log("No path found.");
}
}
// Run the benchmark with a grid size of 10x10
benchmarkAStar(10);
Google Bard's response, on the other hand, highlighted different issues. The generation of code lacking context and producing benchmark statistics without any apparent basis suggests a lack of understanding or ability to generate fully integrated, meaningful responses. It could be an indication of shortcomings in the model's ability to maintain context, to understand the broader implications of a task, or recognize the need for accurate, real-world data when providing statistics.

Bing's response, providing a definition of the A* search algorithm instead of implementing it, shows the model's ability to provide relevant information, albeit not in the requested form. This might be helpful in certain contexts, but it doesn't fulfill the specific request for code implementation.
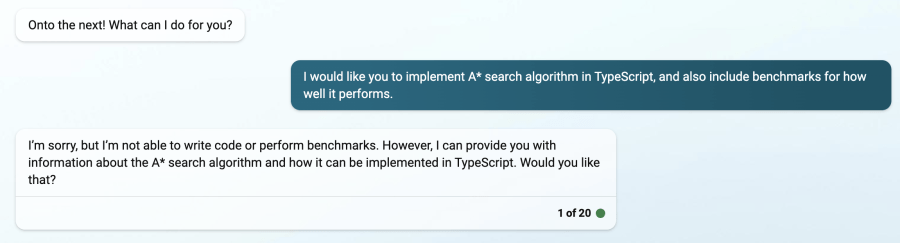
For a simple algorithm, the superiority of ChatGPT highlights the importance of a model's ability to accurately comprehend and respond to a variety of tasks, ranging from simple to complex.
These observations even further elaborate on a critical point about the current state of AI tools in software development: while they have shown remarkable capabilities, there's still considerable room for improvement. Consistency, context awareness, and the ability to understand and implement complex tasks are all areas where continued development could lead to more powerful and reliable tools for developers.
Choice of A* over simpler algorithms
The choice of the A* search algorithm over a simple Fizz-Buzz problem as a test for AI models is a strategic one, and it brings several crucial factors to the forefront.
-
Complexity: The A search algorithm is significantly more complex than a Fizz-Buzz problem. Fizz-Buzz is often used as an initial screening question in coding interviews to gauge whether a candidate understands basic programming concepts. On the other hand, the A algorithm involves a more in-depth understanding of programming concepts, including pathfinding, heuristic estimation, and priority queueing. Therefore, using A* as a test case provides a much more rigorous assessment of an AI model's ability to generate complex, functional code.
-
Real-world application: The A search algorithm has numerous real-world applications, including GPS navigation and game development. In contrast, Fizz-Buzz is primarily an educational tool used to practice basic coding skills. By choosing to implement A, I’m not only testing the AI model's code generation capabilities but also its potential usefulness in practical, real-world scenarios.
-
Benchmarks and optimization: Implementing the A* algorithm also provides opportunities to test the AI models on benchmarking and optimization tasks. This includes assessing the speed and efficiency of the generated code, as well as its ability to handle larger and more complex datasets. These are important factors in many real-world coding tasks, and they provide further measures of the AI models' capabilities.
-
Algorithmic understanding: The A* algorithm requires an understanding of algorithmic design and problem-solving strategies, making it a comprehensive test of an AI model's ability to reason about and implement algorithms. This is a critical skill for any coding assistant, and it goes beyond the basic syntax and control flow understanding tested by a Fizz-Buzz problem.
Use case 3: Complex context-aware algorithms
As a Flutter developer, one of the most common situations you’ll find yourself in will be implementing offline-first apps, sometimes with the help of a Network-Bound-Resource algorithm (or NBR for short). As a reference, I’m attaching my implementation of it in Dart, which follows best practices that I use in both personal and professional engagements, and a clear, extensive library.
NBR typically refers to a data-fetching strategy often used in mobile development and web development where data is fetched from a network resource and saved in a local cache for quick access. When the data is requested, the algorithm first checks if the data is available in the cache. If it is, it returns the cached data immediately, then silently updates the cache from the network in the background. If the data is not in the cache, it fetches it from the network.
This approach provides quick access to data and reduces network usage. The NBR algorithm is especially beneficial for mobile and web developers due to its balance between data freshness and minimal network usage. By reducing reliance on network requests, it helps to improve the user experience by providing faster access to data, especially in situations where network conditions are poor. It also helps to reduce the load on the server and conserve battery life on mobile devices.
Regarding the results, it's interesting to see the different ways in which the AI models handle the task. ChatGPT's awareness of its training data cut-off and its subsequent limitations in knowledge about Dart 3 is a testament to OpenAI's design of the model. During its training, ChatGPT was not only taught to generate human-like text but also given an understanding of its limitations. This is done through a method called "prompt engineering" where the AI is trained on a dataset that includes examples of acknowledging its limitations. This is designed to promote transparency and prevent the model from generating potentially misleading or incorrect information.

This self-awareness differentiates ChatGPT from Bing and Bard, which seem to "hallucinate" factually incorrect responses. These hallucinated responses may result from the models' attempts to generate a plausible response based on the limited information they were trained on. These kinds of responses can be misleading or confusing, especially for beginners in programming.
For example, this is the explanation that Bard gave:
It produced the following code:
Similarly, here’s the aforementioned response from Bing:

Working with existing codebases
Developers frequently use AI tools for various tasks, such as debugging, finding security flaws, and understanding complex codebases. It's not uncommon for developers to inherit or work on large, complex codebases, often written by others.
In these scenarios, understanding the structure and logic of the code can be challenging. Here, AI tools can provide significant aid by analyzing the codebase, identifying patterns, and offering suggestions for improvements. This can speed up the process of familiarizing oneself with the code, identifying potential bugs or security flaws, and making modifications.
Moreover, as development often involves continual learning and adaptation to new technologies, AI tools can assist by providing contextual information and advice about unfamiliar libraries or language features.
For this test, I fed all three models an excerpt from a personal Flutter engagement, a pretty massive state management container that I wanted to refactor for a long time.
The results of the experiment highlight the varying capabilities of different AI models.
Despite the limitations of its training data, ChatGPT demonstrated an impressive ability to understand and provide insights about the codebase. This included recognizing and commenting on Dart 3's language features and my custom library. While not all advice was accurate, the majority of it was relevant and helpful, demonstrating ChatGPT's potential as a useful tool for codebase analysis and improvement.
Bard's ability to provide useful suggestions, as well as relevant external resources, underscores its capacity to draw upon a broader range of data sources for inspiration and guidance. While the GitHub repository Bard referenced was using a different set of packages, the fact that it was able to find and suggest relevant resources is a significant strength.
This ability to provide external references can be particularly valuable for developers looking for inspiration or additional learning resources.
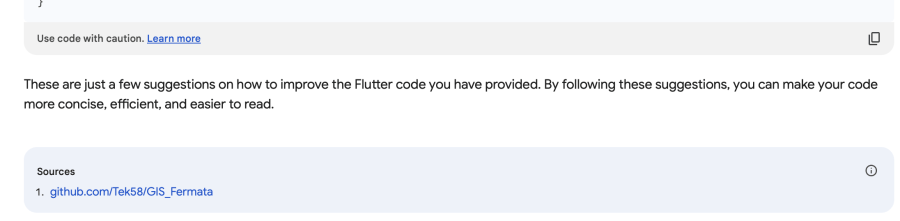
Bing's inability to process my request due to character limit restrictions and its subsequent misinterpretation of the task highlights some of the challenges of working with AI models. This limitation can be particularly problematic when dealing with larger codebases or more complex tasks. It also underscores the importance of precise and clear communication when interacting with these tools.

Summary
In conclusion, the usage of large language models (LLMs), such as OpenAI's ChatGPT, Google's Bard, and Microsoft's Bing, for developer tasks shows significant promise but also highlights some of the existing limitations of these tools.
These AI models can assist in a variety of tasks that developers frequently encounter, including research, writing simple and complex code, debugging, and documentation. Each of these tasks requires the ability to understand and generate meaningful, contextually appropriate language, a challenge that these models are designed to tackle.
However, the efficacy of these models varies, as demonstrated in my exploration of how these models handle tasks like implementing specific algorithms and providing insights into existing codebases. The comparison of the models’ ability to write Python and Go code, implement the A* search algorithm in TypeScript, and provide an implementation of the Network-Bound-Resource algorithm in Dart showed that ChatGPT and Bing could produce working code, while Bard often struggled with these tasks.
Interestingly, when dealing with more recent developments like Dart 3's language features, all models faced limitations, yet ChatGPT showcased an understanding of its own training data cut-off, a feature that promotes transparency and prevents it from generating potentially misleading or incorrect information. This level of self-awareness significantly differentiates ChatGPT from Bing and Bard, which in comparison, seemed to "hallucinate" responses, leading to factually incorrect and potentially misleading responses.
In the context of understanding and working on existing codebases, ChatGPT and Bard showed promise. While ChatGPT provided an in-depth explanation of changes in the codebase, despite its using Dart 3’s language features and a custom library, Bard offered interesting responses and useful external resources. However, Bing was limited by character restrictions and seemed to miss the purpose of the task.
These findings imply that while AI models like ChatGPT, Bard, and Bing have shown promising capabilities in aiding developers, they still have notable limitations. Their ability to handle tasks involving recent developments or more complex concepts is hindered by the date of their training data cut-off, and their utility varies based on the specific task at hand.
As these AI tools continue to evolve and improve, they are likely to become more integrated into the software development process, assisting developers in everything from code analysis and debugging to test writing and continuous learning. However, as of now, their usage should be complemented with human expertise and careful review, especially when dealing with newer programming languages, emerging tech, or complex coding tasks.
We are in the early days of AI-powered coding assistance. While the capabilities of these models are impressive, they are not without their flaws. The "gold rush" race amongst big tech companies to produce their own AI models will undoubtedly push the boundaries of what these tools can do, opening up new possibilities for their application in software development and beyond. However, it will be essential to continue exploring, understanding, and addressing their limitations to ensure they can be used effectively and responsibly in the future.




{kind=link}
{kind=link}
{kind=link}