
João M.
Deep Learning Research Engineer
Han är specialiserad på att bygga avancerade modeller, inklusive stora språkmodeller (LLM), kapabel till kodrefactoring, feldetektering och kontinuerlig inlärning. João arbetar mycket med PyTorch och distribuerar modeller på molnplattformar och högpresterande datorsystem.
Innan ASML ledde han forskargrupper vid GAIPS Lab, publicerade i ledande AI-konferenser, och säkrade bidrag från USA Flygvapnet och FCT. Han undervisade också i AI-kurser, han fick ett pedagogiskt excellenspris för sina bidrag till utbildningen.
João spetsprojekt omfattar fortlöpande inlärningsteknik, vilket gör det möjligt för AI att förvärva ny kunskap utan att glömma tidigare uppgifter, och tillämpa förstärkning lära sig att träna modeller mer effektivt med mindre data. Han brinner för att göra AI-system mer effektiva, praktiska och ständigt förbättra.
Huvudsaklig expertis
Erfarenhet4

Deep Learning Research Engineer
- Ledde en forskargrupp på projektet "LLMs for Software Engineering" med fokus på teknisk skuldminskning, felsökning, och dokumentation analys med hjälp av stora språkmodeller.
- Utformas, implementeras, utbildas, testas och distribueras LLMs för automatisk kod refactoring och felsökning.
- Distribuerade modeller till molnproduktionsmiljöer och HPC distribuerade datorkluster.
- Övervakade den kontinuerliga prestandan hos utplacerade modeller med verktyg som MLFlow, Heliga och vikter & Biases.
- Ansluten företagets forskningsavdelning med akademiska partners på TU/e.
Deep Learning Research Engineer
- Utformad, implementerad, utbildad, testad och implementerad state-of-the-art djuplärande arkitekturer, inklusive Actor-Critics, DQNs, och LLM, med hjälp av konvolutionella, återkommande och uppmärksamhetsbaserade mekanismer för extrahering av funktioner över ett brett spektrum av uppgifter.
- Utplacerade modeller till molnproduktionsmiljöer på plattformar som Google Cloud, Amazon AWS och Slurm HPC distribuerade datorkluster.
- Övervakade den kontinuerliga prestandan hos utplacerade modeller med verktyg som MLFlow, Heliga och vikter & Biases.
- Monterade företagets HPC Slurm kluster.
- Ledde fem forskargrupper som första författare, publicera en forskningspapper för varje i top-tier AI arenor, inklusive AAAI, IJCAI, ECAI, the Artificial Intelligence Journal, och PLoS One Journal.
- Presenterade AI-forskning på toppnivå-internationella konferenser som AAI, IJCAI och ECAI.
- Säkerställde två konkurrenskraftiga finansieringsbidrag, ett från USA. Air Force Office of Scientific Research och en annan från den portugisiska stiftelsen för vetenskap och teknik (FCT).
- Mottog utmärkelsen Best Paper för projektet ”Hjälpa människor på fly: Ad Hoc Teamwork for Human-Robot Team.”

Software Engineer
- Minskad teknisk skuld och ökad total testtäckning av Top Sky Tower -lösningen, ett verktyg för flygledare att hantera elektroniska remsor.
- Implementerade och testade säkerhetssystem
Software Engineer
- Utbildade ett Convolutional Neural Network för att klassificera giltiga identitetskortsbilder.
- Implementerad programvara för automatisk och periodisk säkerhetskopiering av universitetets register till AWS moln.
- Re-implementerad äldre programvara med modern teknik som Scala och Kotlin.
Granskning
Ingenjörsexcellens
João totala prestation i en 90-minuters live-teknisk bedömning rankas inom top 5% av granskade Deep Learning Research Engineer på Proxify.
Portfölj
Markerad av João
 1
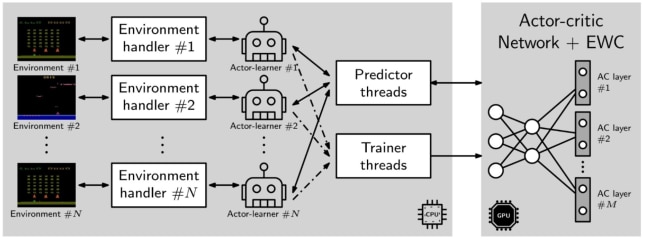
1This project investigates two hypothesis regarding the use of deep reinforcement learning in multiple tasks. The first hypothesis is driven by the question of whether a deep reinforcement learning algorithm, trained on two similar tasks, is able to outperform two single-task, individually trained algorithms, by more efficiently learning a new, similar task, that none of the three algorithms has encountered before. The second hypothesis is driven by the question of whether the same multi-task deep RL algorithm, trained on two similar tasks and augmented with elastic weight consolidation (EWC), is able to retain similar performance on the new task, as a similar algorithm without EWC, whilst being able to overcome catastrophic forgetting in the two previous tasks. We show that a multi-task Asynchronous Advantage Actor-Critic (GA3C) algorithm, trained on Space Invaders and Demon Attack, is in fact able to outperform two single-tasks GA3C versions, trained individually for each single-task, when evaluated on a new, third task—namely, Phoenix.
We also show that, when training two trained multi-task GA3C algorithms on the third task, if one is augmented with EWC, it is not only able to achieve similar performance on the new task, but also capable of overcoming a substantial amount of catastrophic forgetting on the two previous tasks.
Andra projekt 3


Utbildning

Sluta bläddra.
Få matchad snabbare.
Prata med en expert och få skräddarsydda matchningar från vårt nätverk på bara 2 dagar.
Tillgång till över 6 000+ experter
Hitta en utvecklare i genomsnitt 2 dagar
Anställ snabbt och enkelt med 94% matchningsframgång