
João M.
Deep Learning Research Engineer
Er ist spezialisiert auf die Entwicklung fortschrittlicher Modelle, einschließlich großer Sprachmodelle (LLMs), die in der Lage sind, Code Refactoring, Fehlererkennung und kontinuierliches Lernen zu erstellen. João arbeitet umfassend mit PyTorch zusammen und stellt Modelle auf Cloud-Plattformen und Hochleistungsrechnersystemen zur Verfügung.
Vor ASML leitete er Forschungsteams bei GAIPS Lab, publizierte auf führenden KI-Konferenzen und sicherte sich Wettbewerbszuwendungen aus den USA. Luftwaffe und FCT. Er unterrichtete auch KI-Kurse und erhielt für seine Beiträge zur Bildung einen "Teaching Excellence Award".
Zu den wichtigsten Projekten von João gehören die Weiterentwicklung kontinuierlicher Lerntechniken, die es der KI ermöglichen, neues Wissen zu erwerben, ohne vorherige Aufgaben zu vergessen, und die Anwendung des Verstärkungslernens, um Modelle effizienter mit weniger Daten zu trainieren. Er ist leidenschaftlich darum bemüht, die KI-Systeme effektiver, praktischer und ständig zu verbessern.
Hauptkompetenz
Erfahrung4

Deep Learning Research Engineer
- Ein Forschungsteam am Projekt "LLMs for Software Engineering" mit Schwerpunkt auf der technischen Schuldenreduzierung, Fehlererkennung und Dokumentationsanalyse mit Hilfe von Large Language Models.
- Entwickelt, implementiert, geschult, getestet und implementiert LLMs zur automatischen Code-Refactoring und Fehlererkennung.
- Deployed models to cloud production environments and HPC distributed computing cluster.
- Überwachung der kontinuierlichen Leistung der eingesetzten Modelle mit Werkzeugen wie MLFlow, Sacred und Weights & Biases.
- Verbunden der Forschungsabteilung des Unternehmens mit akademischen Partnern bei TU/e.
Deep Learning Research Engineer
- Entwickelt, implementiert, geschult, getestet und implementiert modernste Tieflernarchitekturen, einschließlich Schauspielerkritik, DQNs, und LLMs mit Hilfe von konvolutionären, wiederkehrenden und aufmerksamkeitsbasierten Mechanismen zur Leistungsextraktion über eine Vielzahl von Aufgaben.
- Verteilte Modelle für Cloud-Produktionsumgebungen auf Plattformen wie Google Cloud, Amazon AWS und Slurm HPC verteilte Computercluster.
- Überwachung der kontinuierlichen Leistung von eingesetzten Modellen mit Werkzeugen wie MLFlow, Sacred und Weights & Biases.
- Anordnung des HPC Slurm Clusters.
- Led fünf Forschungsteams als erster Autor, veröffentlicht ein Forschungsdokument für jeden in Top-AI-Veranstaltungsorte, einschließlich AAAI, IJCAI, ECAI, dem Artificial Intelligence Journal, und PLoS One Journal.
- Präsentation der AI-Forschung auf internationalen Top-Konferenzen wie AAI, IJCAI und ECAI.
- Sicherung von zwei wettbewerbsfähigen Fördergeldern, einer aus den USA. Air Force Office of Scientific Research und ein weiteres von der Portugiesischen Stiftung für Wissenschaft und Technologie (FCT).
- Erhalten des Best Paper Award für das Projekt „Helping People On The Fly: Ad Hoc Teamwork for Human-Robot Teams.“

Software Engineer
- Reduzierte technische Schulden und eine erhöhte Gesamtprüfung der Top Sky Tower Lösung, ein Werkzeug für die Fluglotsen zur Verwaltung von elektronischen Streifen.
- Implementierte und getestete kritische Sicherheitserkennungssysteme.
Software Engineer
- Ein Neuronales Netzwerk ausgebildet, um gültige Identitätskartenbilder zu klassifizieren.
- Implementierte Software für automatische und periodische Sicherungen der Universitätsdatensätze in der AWS-Cloud.
- Reimplementierte Legacy-Software mit modernen Technologien wie Scala und Kotlin.
Eignungstests
Excellence en ingénierie
João Gesamtleistung in einer 90-minütigen Live-Technikbewertung rangiert im top 5% der überprüften Deep Learning Research Engineer bei Proxify.
Portfolio
Hervorgehoben von João
 1
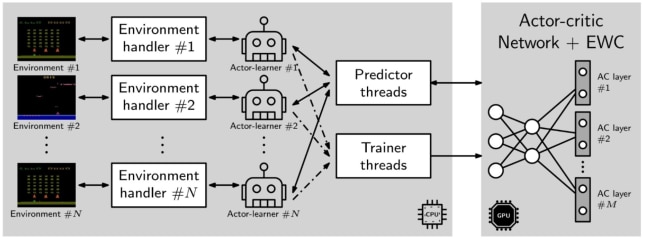
1This project investigates two hypothesis regarding the use of deep reinforcement learning in multiple tasks. The first hypothesis is driven by the question of whether a deep reinforcement learning algorithm, trained on two similar tasks, is able to outperform two single-task, individually trained algorithms, by more efficiently learning a new, similar task, that none of the three algorithms has encountered before. The second hypothesis is driven by the question of whether the same multi-task deep RL algorithm, trained on two similar tasks and augmented with elastic weight consolidation (EWC), is able to retain similar performance on the new task, as a similar algorithm without EWC, whilst being able to overcome catastrophic forgetting in the two previous tasks. We show that a multi-task Asynchronous Advantage Actor-Critic (GA3C) algorithm, trained on Space Invaders and Demon Attack, is in fact able to outperform two single-tasks GA3C versions, trained individually for each single-task, when evaluated on a new, third task—namely, Phoenix.
We also show that, when training two trained multi-task GA3C algorithms on the third task, if one is augmented with EWC, it is not only able to achieve similar performance on the new task, but also capable of overcoming a substantial amount of catastrophic forgetting on the two previous tasks.
Andere Projekte 3


Ausbildung

Hör auf zu stöbern.
Lass dich schneller matchen.
Sprechen Sie mit einem Experten und erhalten Sie innerhalb von nur 2 Tagen maßgeschneiderte Matches aus unserem Netzwerk.
Zugriff auf über 6.000+ Experten
Werden Sie im Durchschnitt in 2 Tagen mit einem Entwickler zusammengebracht
Schnell und einfach einstellen mit 94% Übereinstimmungserfolg