
João M.
Deep Learning Research Engineer
Hij is gespecialiseerd in het bouwen van geavanceerde modellen, waaronder large language models (LLM’s), die in staat zijn tot code-refactoring, bugdetectie en continual learning. João werkt intensief met PyTorch en implementeert modellen op cloudplatforms en high-performance computing-systemen.
Voor zijn tijd bij ASML leidde hij onderzoeksteams bij GAIPS Lab, publiceerde hij op toonaangevende AI-conferenties en verkreeg hij competitieve onderzoeksbeurzen van de U.S. Air Force en FCT. Daarnaast gaf hij AI-cursussen en ontving hij een Teaching Excellence Award voor zijn bijdragen aan het onderwijs.
João’s belangrijkste projecten omvatten het ontwikkelen van technieken voor continual learning, waarmee AI nieuwe kennis kan verwerven zonder eerdere taken te vergeten, en het toepassen van reinforcement learning om modellen efficiënter te trainen met minder data. Hij is gepassioneerd over het effectiever, praktischer en voortdurend verbeterend maken van AI-systemen.
Hoofd expertise
Ervaring4

Deep Learning Research Engineer
- Led een onderzoeksteam over de "LM's for Software Engineering" project, gericht op technische schuldvermindering, foutopsporing en documentatie analyse met behulp van grote taalmodellen.
- Ontworpen, geïmplementeerd, getraind, getest en ingezette LLMs voor automatische code-refactoring en bug detectie.
- Gebruik van modellen om productie-omgevingen en HPC computerclusters te verdelen.
- Gevolgde de voortdurende prestaties van ingezette modellen met behulp van gereedschappen zoals MLFlow, Heilige en Gewichten & Biases.
- Verbonden de onderzoeksafdeling van het bedrijf met academische partners bij TU/e.
Deep Learning Research Engineer
- Ontworpen en geïmplementeerd, getraind, getest en inzette de nieuwste architecturen voor diep leren, waaronder Actor-Critics, DQNs, en LLM's met behulp van convolutionele, herhalende en attentiegebaseerde mechanismen voor het extraheren van functies over een breed scala aan taken.
- Uitgezette modellen om productieomgevingen te cloud op platformen zoals Google Cloud, Amazon AWS en Slurm HPC gedistribueerde computerclusters.
- Gevolgde de voortdurende prestaties van ingezette modellen met behulp van gereedschappen als MLFlow, Heilige Stoelen, Gewichten & Biases.
- Verzamel het HPC Slurm-cluster van het bedrijf.
- Vijf onderzoeksteams als eerste auteur, publicatie van een onderzoeksdocument voor elke toptier AI locaties, inclusief AAI, IJCAI, ECAI, het Kunstmatige Intelligentie Journal en PLoS One Journal.
- Gepresenteerd AI onderzoek bij internationale topconferenties zoals AAAI, IJCAI en ECAI.
- Twee subsidies voor concurrerende concurrentie werden veiliggesteld, één van de Amerikaanse subsidies. De oprichting van een luchtmacht voor wetenschappelijk onderzoek en een andere organisatie van de Portugese Stichting voor Wetenschap en Technologie (FCT).
- De beste Papier beloning ontvangen voor het project "Mensen helpen in de Fly: Advertentie Hoc Teamwork voor teams voor Human-Robot."

Software Engineer
- Verminderde technische schulden en verhoogde algemene testdekking voor de oplossing van de top Sky Tower , een instrument voor luchtverkeersleiders om elektronische strips te beheren.
- Uitgevoerde en geteste kritieke beveiligingsdetectiesystemen.
Software Engineer
- Een Convolutioneel Neurale Netwerk voor de classificatie van geldige identiteitskaarten.
- Uitgevoerde software voor automatische en periodieke back-ups van de gegevens van de universiteit naar de AWS-cloud.
- oude software opnieuw geïmplementeerd met behulp van moderne technologieën zoals Scala en Kotlin.
Beoordeling
Uitmuntendheid in techniek
João algemene prestaties in een 90-minuten durende technische beoordeling zijn in de top 5% van de gescreende Deep Learning Research Engineer bij Proxify.
Portefeuille
Uitgelicht door João
 1
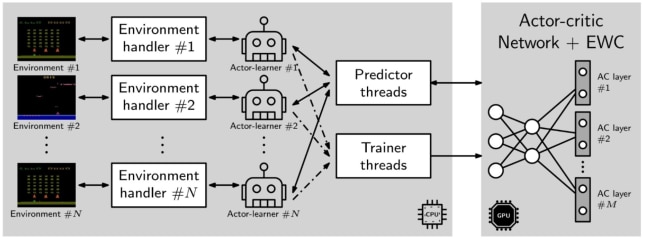
1This project investigates two hypothesis regarding the use of deep reinforcement learning in multiple tasks. The first hypothesis is driven by the question of whether a deep reinforcement learning algorithm, trained on two similar tasks, is able to outperform two single-task, individually trained algorithms, by more efficiently learning a new, similar task, that none of the three algorithms has encountered before. The second hypothesis is driven by the question of whether the same multi-task deep RL algorithm, trained on two similar tasks and augmented with elastic weight consolidation (EWC), is able to retain similar performance on the new task, as a similar algorithm without EWC, whilst being able to overcome catastrophic forgetting in the two previous tasks. We show that a multi-task Asynchronous Advantage Actor-Critic (GA3C) algorithm, trained on Space Invaders and Demon Attack, is in fact able to outperform two single-tasks GA3C versions, trained individually for each single-task, when evaluated on a new, third task—namely, Phoenix.
We also show that, when training two trained multi-task GA3C algorithms on the third task, if one is augmented with EWC, it is not only able to achieve similar performance on the new task, but also capable of overcoming a substantial amount of catastrophic forgetting on the two previous tasks.
Andere projecten 3


Educatie

Stop met browsen.
Word sneller gekoppeld.
Praat met een expert en krijg binnen 2 dagen op maat gemaakte matches uit ons netwerk.
Toegang tot meer dan 6.000+ experts
Word binnen gemiddeld 2 dagen gekoppeld aan een ontwikkelaar
Huur snel en eenvoudig in met 94% matchingsucces