
João M.
Deep Learning Research Engineer
Han har spesialisert seg på å bygge avanserte modeller, inkludert store språkmodeller (LLM-er), som kan utføre kode-refaktorering, feildeteksjon og kontinuerlig læring. João arbeidet omfattende med PyTorch og deployerte modeller på skyplattformer og høyytelses datasystemer.
Før ASML ledet han forskerteam ved GAIPS Lab, publiserte i ledende AI-konferanser, og sikret konkurransedyktige forskningsmidler fra den amerikanske flyvåpenet og FCT. Han underviste også i AI-kurs og mottok en Teaching Excellence Award for sitt bidrag til undervisning.
Joãos nøkkelprosjekter inkluderte utvikling av teknikker for kontinuerlig læring, som gjorde det mulig for AI å tilegne seg ny kunnskap uten å glemme tidligere oppgaver, og bruk av forsterkende læring for å trene modeller mer effektivt med mindre data. Han brenner for å gjøre AI-systemer mer effektive, praktiske og stadig bedre.
Hovedekspertise
Erfaring4

Deep Learning Research Engineer
- Led a research team on the "LMs for Software Engineering" prosjekt med fokus på teknisk gjeldsreduksjon, Feildeteksjon og dokumentasjonsanalyse ved hjelp av store språkmodeller.
- Desiged, implemented, trained, testet, and deployed LLMs for automatic code refactoring and bug detection.
- Utsatte modeller til sky-produksjonsmiljøer og HPC distribuerte dataprogramklynger.
- Overvåket den kontinuerlige ytelsen til modeller med verktøy som MLFlow, Sacred og Weights & Biases.
- Tilkoblingen til selskapets forskningsavdeling med akademiske partnere ved TU/e.
Deep Learning Research Engineer
- Prosjektert, implementert, trenet, testet, og distribuert toppmoderne læringsarkitekter, som for eksempel Actor-Critics, DQN, LL-er og LM ved bruk av konvolusjonale, gjentakende og oppmerksomhetsbaserte mekanismer for nedtrekksvirksomhet på tvers av mange oppgaver.
- Distribuerte modeller til skytjenester på plattformer som Google Cloud, Amazon AWS, og Slurm HPC distribuerte dataklubstre.
- Overvåket den kontinuerlige ytelsen til modeller ved bruk av verktøy som MLFlow, Sacred og Weights & Biases.
- Sammensatte selskapets HPC Slurm klyngere.
- Led fem forskerteam som førstegangsforfatter og offentliggjør en forskningsrapport til hvert trinn i nivå AI i arenaer. herunder AAAI, IJCAI, ECAI, the tificial Intelligence Journal, and PLoS One Journal.
- Presented AI-forskning på internasjonale topp-nivå konferanser som AAAI, IJCAI og ECAI.
- Sikret to konkurransepregede tilskudd, ett fra USA Air Force Office of Scientific Research og et annet fra det portugisiske stiftelsen for Science and Technology (FCT).
- Mottok prisen for beste papir for prosjektet «Helping People On The Fly: Ad Hoc Teamwork for Human-Robot Teams.»

Software Engineer
- Redusert teknisk gjeld og økt samlet testdekning av løsningen med Top Sky Tower, et verktøy til lufttrafikktjenesten for å håndtere elektroniske striper.
- Implementerte og testede kritiske systemer for deteksjon av sikkerhet.
Software Engineer
- Trent et Convolusjonalt nevrale nettverk for å klassifisere gyldige bilder av identitetskort.
- Implementert programvare for automatiske og periodiske sikkerhetskopieringer av universitetets registre til AWS-skyen.
- Reimplementert eldre programvare med bruk av moderne teknologier som Scala og Kotlin.
Vurdering
Ingenieurskunst der Spitzenklasse
João totale ytelse i en 90-minutters live teknisk vurdering rangerer i de top 5% av vurderte Deep Learning Research Engineer hos Proxify.
Portefølje
Fremhevet av João
 1
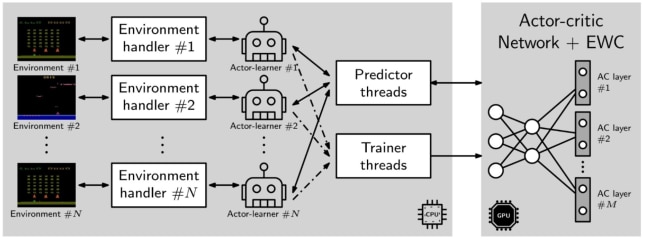
1This project investigates two hypothesis regarding the use of deep reinforcement learning in multiple tasks. The first hypothesis is driven by the question of whether a deep reinforcement learning algorithm, trained on two similar tasks, is able to outperform two single-task, individually trained algorithms, by more efficiently learning a new, similar task, that none of the three algorithms has encountered before. The second hypothesis is driven by the question of whether the same multi-task deep RL algorithm, trained on two similar tasks and augmented with elastic weight consolidation (EWC), is able to retain similar performance on the new task, as a similar algorithm without EWC, whilst being able to overcome catastrophic forgetting in the two previous tasks. We show that a multi-task Asynchronous Advantage Actor-Critic (GA3C) algorithm, trained on Space Invaders and Demon Attack, is in fact able to outperform two single-tasks GA3C versions, trained individually for each single-task, when evaluated on a new, third task—namely, Phoenix.
We also show that, when training two trained multi-task GA3C algorithms on the third task, if one is augmented with EWC, it is not only able to achieve similar performance on the new task, but also capable of overcoming a substantial amount of catastrophic forgetting on the two previous tasks.
Andre prosjekter 3


Utdannelse

Slutt å bla.
Bli matchet raskere.
Snakk med en ekspert og få skreddersydde matcher fra vårt nettverk på bare 2 dager.
Få tilgang til over 6 000+ eksperter
Få en utvikler tilpasset dine behov i løpet av gjennomsnittlig 2 dager
Ansett raskt og enkelt med 94% match suksess