
João M.
Deep Learning Research Engineer
Hän on erikoistunut rakentamaan kehittyneitä malleja, mukaan lukien suuria kielimalleja (LLM), jotka kykenevät koodinkorjaukseen, vikojen havaitsemiseen ja jatkuvaan oppimiseen. João toimii laajasti PyTorchin kanssa ja hyödyntää malleja pilvialustoilla ja korkean suorituskyvyn laskentajärjestelmissä.
Ennen ASML, hän johti tutkimusryhmien GAIPS Lab, joka on julkaistu johtava tekoälykonferensseja, ja turvattu kilpailukykyisiä avustuksia Yhdysvalloista. Ilmavoimat ja FCT. Hän opetti myös tekoälykursseja, ansaitsemalla opetus Excellence Award -palkinnon hänen panoksestaan koulutukseen.
João keskeisiä projekteja ovat jatkuvan oppimisen tekniikoiden kehittäminen, joka mahdollistaa uuden tiedon hankkimisen unohtamatta aikaisempia tehtäviä. ja tehostamalla oppimista kouluttamaan malleja entistä tehokkaammin vähemmillä tiedoilla. Hän on intohimoinen tehdessään tekoälyn järjestelmistä tehokkaampia, käytännöllisempiä ja jatkuvasti parempia.
Tärkein asiantuntemus
Kokemus4

Deep Learning Research Engineer
- Led tutkimusryhmä "LLMs for Software Engineering" -hankkeesta, jossa keskitytään velan tekniseen vähentämiseen, virheentunnistus ja dokumentaatio-analyysi käyttäen suuria kielimalleja.
- Suunniteltu, toteutettu, koulutettu, testattu, ja otettu käyttöön LLM automaattista koodin refactoring ja vikojen havaitseminen.
- Käyttöönotetut mallit pilvituotantoympäristöihin ja suurteholaskentaan jaettuihin tietotekniikkaklustereihin.
- Seurataan käytössä olevien mallien jatkuvaa suorituskykyä käyttäen esimerkiksi MLFlow-, Sacred- ja Painot & Biases-työkaluja.
- Yhtiön tutkimusosasto yhdistettiin akateemisiin kumppaneihin TU/e.
Deep Learning Research Engineer
- Suunnitellut, toteutettu, koulutettu, testattu ja otettu käyttöön huippuluokan syvä oppiminen arkkitehtuurit, mukaan lukien Actor-Critics, DQNs, ja LLM:t, jotka käyttävät vallankumouksellisia, toistuvia ja tarkkaavaisia mekanismeja ominaisuustietojen keräämiseksi monenlaisista tehtävistä.
- Käyttöönotetut mallit pilvipalveluiden tuotantoympäristöihin, kuten Google Cloudiin, Amazon AWS:ään ja Slurm HPC -jakeluklustereihin.
- Seurataan käytössä olevien mallien jatkuvaa suorituskykyä käyttäen esimerkiksi MLFlow-, Sacred- ja Painot & Biases-työkaluja.
- Koottiin yhtiön HPC Slurm klusteri.
- Led viisi tutkijaryhmää kuin ensimmäinen kirjailija, joka julkaisee tutkimuspaperin kunkin huipputason tekoälykohteissa, mukaan lukien AAAI, IJCAI, ECAI, Artificial Intelligence Journal ja PLoS One Journal.
- Esitetty tekoälytutkimus huipputason kansainvälisissä konferensseissa, kuten AAAI, IJCAI ja ECAI.
- Varmistettu kaksi kilpailevaa rahoitusapua, yksi Yhdysvalloista. Air Force Office of Scientific Research ja toinen Portugalin tieteen ja teknologian säätiön (FCT).
- Sai parhaan paperin palkinnon hankkeelle ”Helping People On The FLLy: Ad Hoc Teamwork for Human-Robot Teams.”

Software Engineer
- Teknisen velan väheneminen ja Top Sky Tower -ratkaisun entistä kattavampi testaus, joka on lennonjohtajien työkalu elektronisten nauhojen hallintaan.
- Toteutettu ja testattu kriittisen turvallisuuden havaitsemisjärjestelmät.
Software Engineer
- Koulutettu Convolutional Neural Network luokitella voimassa olevat henkilökorttikuvia.
- Toteutettu ohjelmisto AWS pilven AWS -tietojen automaattiseen ja ajoittaiseen varmuuskopiointiin.
- Uudelleentoteutetut perinteiset ohjelmistot, joissa käytetään nykyaikaisia teknologioita, kuten Scala ja Kotlin.
Arviointi
Tekniikan huippuosaaminen
João yleinen suorituskyky 90 minuutin suorassa teknisessä arvioinnissa on top 5 % Proxifyn tarkastetuista Deep Learning Research Engineer.
Portfolio
Korostanut João
 1
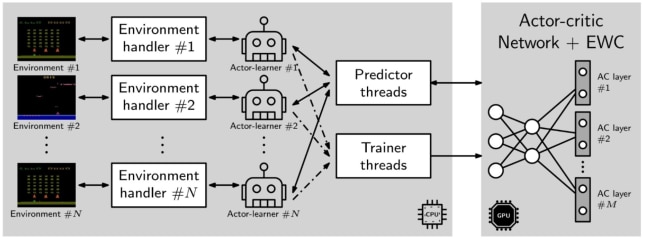
1This project investigates two hypothesis regarding the use of deep reinforcement learning in multiple tasks. The first hypothesis is driven by the question of whether a deep reinforcement learning algorithm, trained on two similar tasks, is able to outperform two single-task, individually trained algorithms, by more efficiently learning a new, similar task, that none of the three algorithms has encountered before. The second hypothesis is driven by the question of whether the same multi-task deep RL algorithm, trained on two similar tasks and augmented with elastic weight consolidation (EWC), is able to retain similar performance on the new task, as a similar algorithm without EWC, whilst being able to overcome catastrophic forgetting in the two previous tasks. We show that a multi-task Asynchronous Advantage Actor-Critic (GA3C) algorithm, trained on Space Invaders and Demon Attack, is in fact able to outperform two single-tasks GA3C versions, trained individually for each single-task, when evaluated on a new, third task—namely, Phoenix.
We also show that, when training two trained multi-task GA3C algorithms on the third task, if one is augmented with EWC, it is not only able to achieve similar performance on the new task, but also capable of overcoming a substantial amount of catastrophic forgetting on the two previous tasks.
Muut projektit 3


Koulutus

Lopeta selaaminen.
Sovitetaan nopeammin.
Keskustele asiantuntijan kanssa ja saat räätälöityjä ehdotuksia verkostostamme vain 2 päivässä.
Pääsy yli 6 000+ asiantuntijaa
Löydä kehittäjä keskimäärin 2 päivässä
Palkkaa nopeasti ja helposti 94% onnistuneella osumalla