
João M.
Deep Learning Research Engineer
Il se spécialise dans la construction de modèles avancés, y compris de grands modèles de langage (LLM), capables de refactoriser le code, de détecter les bugs et de continuer à apprendre. João travaille largement avec PyTorch et déploie des modèles sur des plates-formes cloud et des systèmes informatiques performants.
Avant de participer à l'ASML, il a dirigé des équipes de recherche au Laboratoire GAIPS, publié dans le cadre de conférences d'Amnesty International, et obtenu des subventions de la part des États-Unis. Force aérienne et FCT. Il a également enseigné des cours d’IA, obtenant un prix d’excellence en enseignement pour sa contribution à l’éducation.
Les principaux projets de João comprennent l’avancement des techniques d’apprentissage continuelles, permettant à l’IA d’acquérir de nouvelles connaissances sans oublier les tâches précédentes, et en appliquant l'apprentissage du renforcement pour former des modèles plus efficacement avec moins de données. Il est passionné de rendre les systèmes AI plus efficaces, plus pratiques et en constante amélioration.
Expertise principale
Expérience4

Deep Learning Research Engineer
- Dirigé une équipe de recherche sur le projet "LLMs for Software Engineering", axé sur la réduction technique de la dette, la détection des bogues et l'analyse de la documentation à l'aide de grands modèles de langage.
- Conçu, mis en œuvre, formé, testé et déployé des LLMs pour la refactorisation automatique du code et la détection des bugs.
- Modèles déployés dans les environnements de production de nuages et les clusters de calcul distribués par HPC.
- Surveillé la performance continue des modèles déployés en utilisant des outils tels que MLFlow, Sacred et Weights & Biases.
- Connected the company research department with academic partners at TU/e.
Deep Learning Research Engineer
- Conçu, mis en œuvre, formé, testé et déployé des architectures d’apprentissage approfondi à la fine pointe de la technologie, y compris Actor-Critics, DQNs, et LLMs, en utilisant des mécanismes convolutionnels, récurrents et attentifs pour l'extraction de fonctionnalités dans un large éventail de tâches.
- Des modèles déployés sur des environnements de production cloud sur des plates-formes telles que Google Cloud, Amazon AWS et Slurm HPC ont distribué des grappes informatiques.
- Surveillé la performance continue des modèles déployés en utilisant des outils tels que MLFlow, Sacred et Weights & Biases.
- Assemblage de la grappe HPC Slurm de la société.
- Dirigé cinq équipes de recherche en tant que premier auteur, publiant un document de recherche pour chacun des lieux les plus performants de l’IA, y compris AAAI, IJCAI, ECAI, le Journal Artificial Intelligence et le PLoS One Journal.
- Présentation de la recherche sur les AI lors de conférences internationales de premier rang telles que AAAI, IJCAI et ECAI.
- Sécurisé deux subventions de financement concurrentielles, l'une provenant des États-Unis. Air Force Office of Scientific Research et un autre de la Fondation portugaise pour la Science et la Technologie (FCT).
- Reçu le prix du meilleur papier pour le projet « Aider les gens à la mouche : équipe ad hoc pour les équipes humaines-robotes ».

Software Engineer
- Réduction de la dette technique et augmentation de la couverture globale des tests de la solution Top Sky Tower, un outil destiné aux contrôleurs aériens pour la gestion des bandes électroniques.
- Implémenté et testé systèmes de détection de sécurité critique.
Software Engineer
- Formé un réseau neuronal pour classer les images valides de carte d'identité.
- Logiciel implémenté pour les sauvegardes automatiques et périodiques des dossiers de l'université dans le nuage AWS.
- Remise en œuvre de logiciels anciens utilisant des technologies modernes telles que Scala et Kotlin.
Évaluations
Excellence en ingénierie
Les performances globales de João lors d'une évaluation technique en direct de 90 minutes se classent dans le top 5% des Deep Learning Research Engineer évalués chez Proxify.
Portefeuille
Mis en avant par João
 1
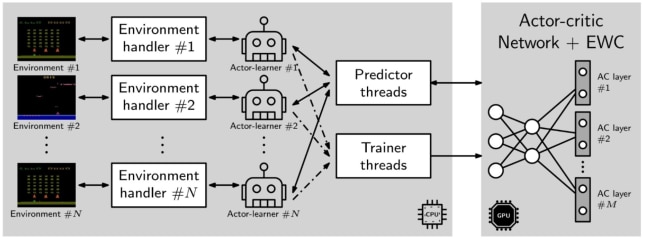
1This project investigates two hypothesis regarding the use of deep reinforcement learning in multiple tasks. The first hypothesis is driven by the question of whether a deep reinforcement learning algorithm, trained on two similar tasks, is able to outperform two single-task, individually trained algorithms, by more efficiently learning a new, similar task, that none of the three algorithms has encountered before. The second hypothesis is driven by the question of whether the same multi-task deep RL algorithm, trained on two similar tasks and augmented with elastic weight consolidation (EWC), is able to retain similar performance on the new task, as a similar algorithm without EWC, whilst being able to overcome catastrophic forgetting in the two previous tasks. We show that a multi-task Asynchronous Advantage Actor-Critic (GA3C) algorithm, trained on Space Invaders and Demon Attack, is in fact able to outperform two single-tasks GA3C versions, trained individually for each single-task, when evaluated on a new, third task—namely, Phoenix.
We also show that, when training two trained multi-task GA3C algorithms on the third task, if one is augmented with EWC, it is not only able to achieve similar performance on the new task, but also capable of overcoming a substantial amount of catastrophic forgetting on the two previous tasks.
Autres projets 3


Éducation

Arrêtez de naviguer.
Soyez jumelé plus rapidement.
Parlez à un expert et obtenez des correspondances personnalisées de notre réseau en seulement 2 jours.
Accédez à plus de 6 000+ experts
Soyez jumelé avec un développeur en 2 jours en moyenne
Embauchez rapidement et facilement avec un taux de réussite de 94%