We require somewhere to store our valuable business data. Data can refer to anything such as users' information, banking transactions, logging texts of an application, real-time changes in prices, and so many more examples.
There are plenty of database types. Such as Relational, NoSQL, In-Memory, NewSQL, Graph, and Time-Series databases. The main goal of this article is to illustrate two of the main topics concerning RDBMS (Relational Database Management System), which are vital for a Senior backend/fullstack engineer to know.
Before delving deep into this article, let's clarify certain concepts.
Database server
A server (computer) on which we run one or more databases. For example, when we create an instance of AWS RDS whose instance class is db.t3.micro, we have reserved a virtual machine to run our database in the cloud.
DBMS
People usually use this term interchangeably with "Database Engine". The core software which handles the queries we send to the database server. In the example above, we can have an AWS RDS instance whose database engine is PostgreSQL or MySQL. This is the core component that stores the data on the disc or creates indexes. DBMS can refer to many types, such as SQLite, Relational, and No-Relational.
RDBMS
The Relational DBMS. This is where the data is structured, and we would like to store it in tables. These tables can be joined together. RDBMS uses SQL (Structured Query Language) as the standard language for querying and manipulating data. Please pay attention that SQL has different dialects, and the SQL syntax may slightly differ depending on your choice. PostgreSQL, MariaDB, and MySQL are some dialects.
How to interact with the database?
Assume you have an application whose backend needs to communicate with a database server. Depending on the programming language and framework in which the backend is written, we can have three approaches to interact with the database server.
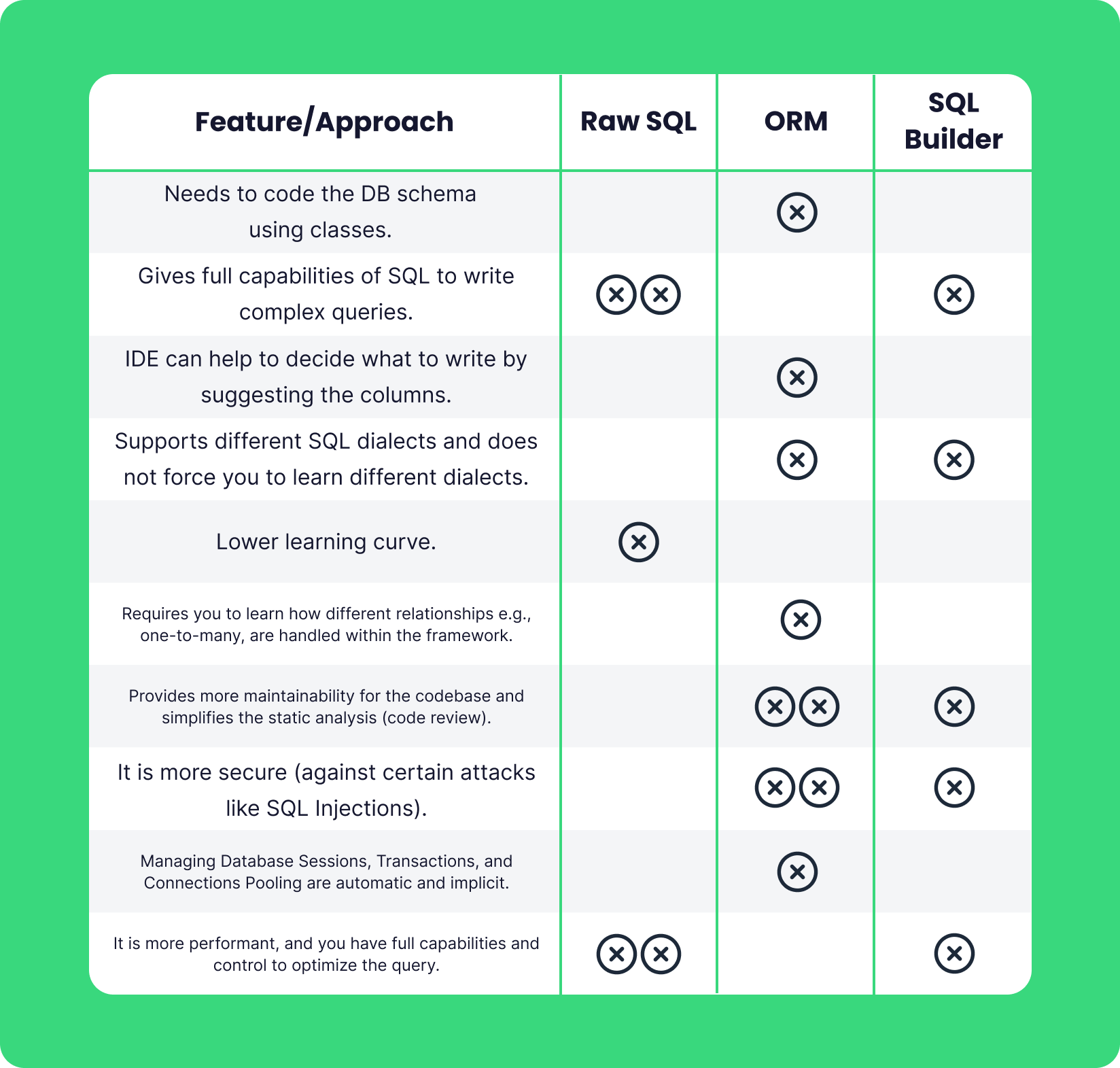
- Raw SQL: When we simply write a query in SQL syntax and directly execute it.
- ORM (Object Relational Mapping): ORM frameworks abstract the database layer, and you can interact with the database in Python and JavaScript instead of writing SQL Syntax directly. All the tables are objects of the programming language of our choice. This approach heavily relies on the Object Oriented paradigm.
- SQL Builder: SQL builder libraries suggest a "compromise" between raw SQL and ORM. They allow you to construct SQL queries programmatically but in a more structured and safe manner than Raw SQL.
In the table below, we have compared these approaches.
For better understanding, we write a query in the approaches above according to the ER (Entity-Relationship) diagram given. This diagram shows the one-to-many relationship from user to post. Please pay attention that we are using Postgres as the SQL dialect.
Query: Get the email and the overall number of the top 3 users with the maximum likes count on ALL their posts. We only want emails ending in ".com."
1. Using RAW SQL in PostgreSQL Dialect:
SELECT SUM(post.likes_count) AS post_likes_count, app_user.email
FROM app_user
INNER JOIN post ON app_user.id = post.user_id
WHERE app_user.email LIKE "%.com"
GROUP BY app_user.id
ORDER BY post_likes_count DESC LIMIT 3;2. Using ORM via SQLAlchemy version 2.0.20
from sqlalchemy.orm import DeclarativeBase, Mapped, relationship, Session, mapped_column
class Base(DeclarativeBase):
pass
class AppUser(Base):
__tablename__ = "app_user"
id: Mapped[int] = mapped_column(primary_key=True)
email: Mapped[str] = mapped_column(String(512), unique=True, nullable=False)
def __repr__(self) -> str:
return f"User(id={self.id!r}, email={self.email!r})"
class Post(Base):
__tablename__ = "post"
id: Mapped[int] = mapped_column(primary_key=True)
content: Mapped[str] = mapped_column(String(512), nullable=False)
likes_count: Mapped[int] = mapped_column(Integer, nullable=False, server_default=text("0"))
user_id: Mapped[int] = mapped_column(ForeignKey("app_user.id"), nullable=False)
user: Mapped["AppUser"] = relationship(backref="posts")
def __repr__(self) -> str:
return f"Post(id={self.id!r}, content={self.content!r}, user_id={self.user_id!r})"
engine = create_engine(URL_OF_DATABASE, echo=False)
with Session(engine) as session:
post_likes_count = func.sum(Post.likes_count).label("post_likes_count")
query = (
select(post_likes_count, AppUser.email)
.join(Post, AppUser.id == Post.user_id)
.where(AppUser.email.like("%.com"))
.group_by(AppUser.id)
.order_by(post_likes_count.desc())
.limit(3)
)
rows = session.execute(query).fetchall() # Retrieves all the rows from the database3. Using Query builder of Pypika version 0.48.9
from pypika import Query, Table, functions, Order
post = Table("post")
app_user = Table("app_user")
post_likes_count = functions.Sum(post.likes_count).as_('post_likes_count')
query = (
Query
.select(post_likes_count, app_user.email)
.where(app_user.email.like("%.com"))
.from_(app_user).join(post).on(app_user.id == post.user_id)
.groupby(app_user.id)
.orderby(post_likes_count, order=Order.desc)
.limit(3)
)
query_syntax = query.get_sql() # We can use DB connectors like psycopg2, pymysq or ORM Libraries like SQLAlchemy
# to execute the query_syntax and retrieve the rowsIndexes
The 2nd topic that we want to go over is about the indexes. Index, as its name implies, resembles a book index. When you want to find a specific topic within the book, you are not required to look at every page to find the topic. You just check the index and easily find it. Ergo, the main reason to build DB indexes is to avoid checking all the rows.
Assume we have the data of users. The table below represents how the data is on the logical level for an RDMBS.
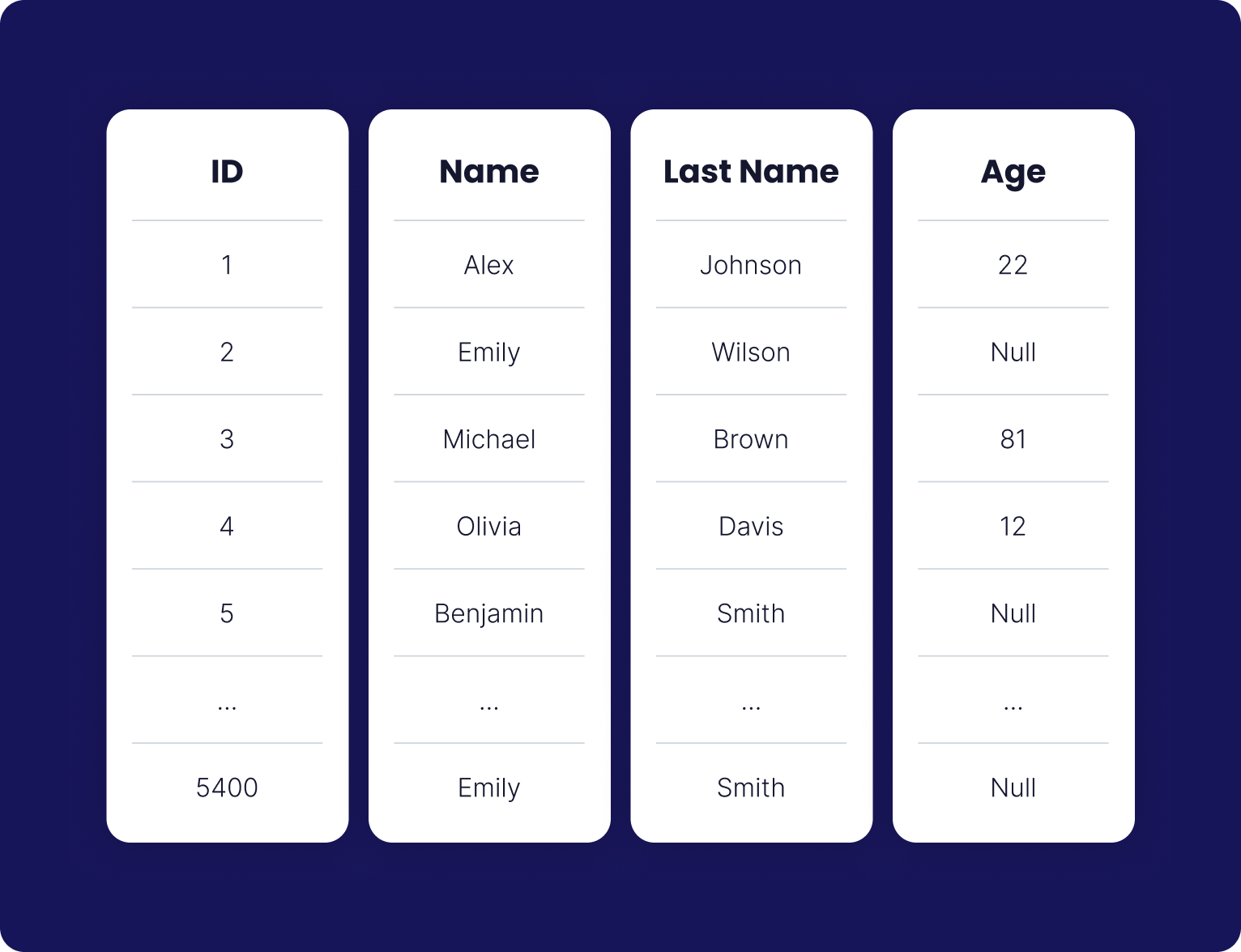
Now assume that we have a primary key that gets incremented per insertion. Therefore, RDBMS creates a clustered Index. This clustered index is a B-tree. B-trees are utilized because of their balanced structure, which allows for efficient insertion, deletion, and retrieval operations. RDMS stores the data on disk based on the Primary key of users data as the Index key in a B-tree.
1. What is a clustered index?
A clustered Index is a B+ tree data structure. A B+ tree is similar to a B-tree, but its leaves are connected through a linked list which makes finding rows much faster as we can iterate over the leaves. Clustered means that the data rows in the leaf nodes are stored in the order of the index key (the Primary Key in our example).
2. What do the leaf nodes store in a clustered Index?
Each leaf node in a clustered index is called a Data Page, which has a fixed size of 8 KB (can be different depending on RDBMS). Each data page contains the actual rows of the data. The number of rows stored on each Data Page can be different.
SELECT *
FROM users
WHERE id = 1205;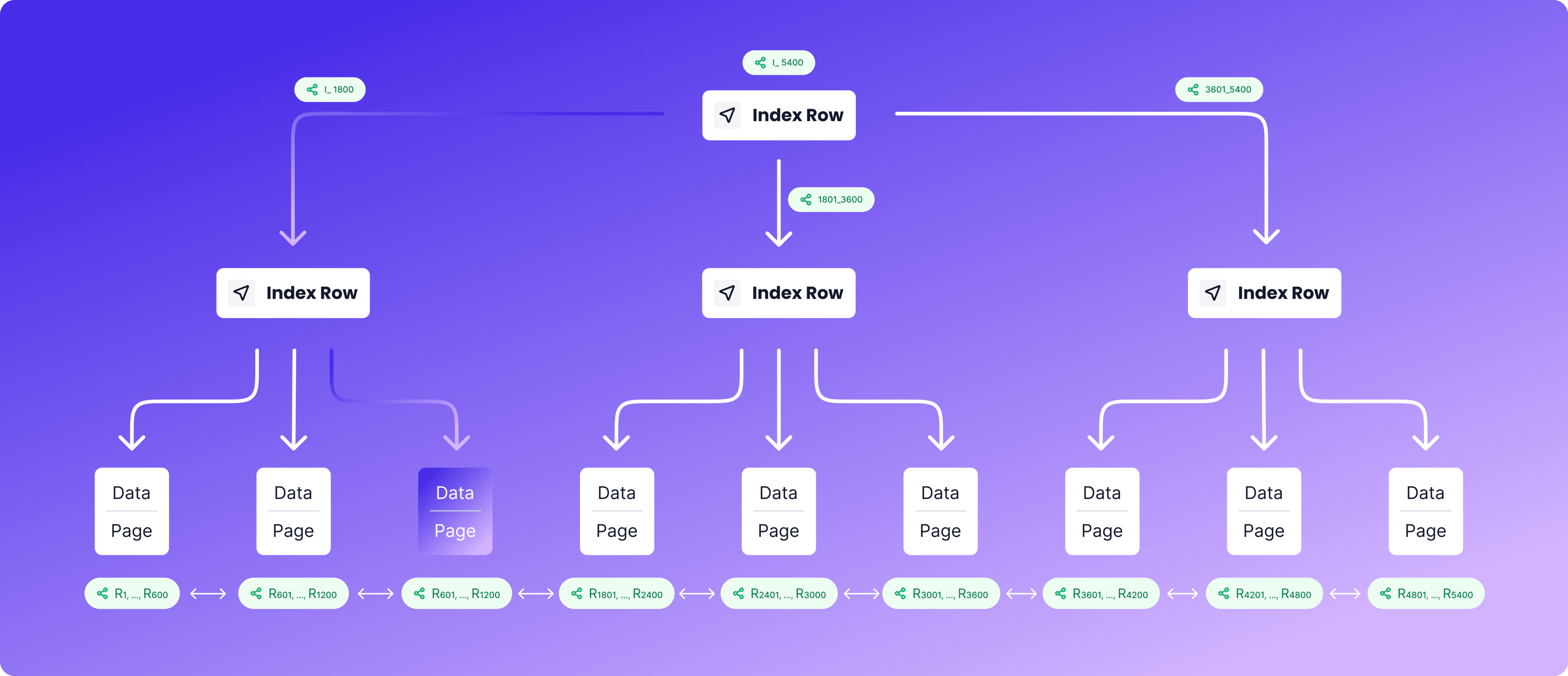
The picture above is a resemblance of the way that an RDBMS stores the primary keys. After the primary key, e.g., 1205 is found within this B+ tree, the RDBMS uses it to easily read the row from the corresponding Data Page.
3. What is a non-clustered Index?
Non-clustered indexes are those whose leaf nodes do not contain all the actual rows (meaning they are not Data Pages). They solely contain the values of the column(s) on which the index is built along with some identifier called RID (Row Identifier) assigned by the DB itself and points to the actual data row location stored on disk. Each leaf is called a Row Locator.
When you create a non-clustered index on, let's say, column X, the database uses all the unique values of X with the corresponding RIDs to create that index. Now let's assume we have created a non-clustered index on columns age, name, and last_name of users data. In the key-value node, each Key is the combination of the indexed columns, and each Value is usually the reference to the actual rows.
The picture below illustrates what this index looks like.
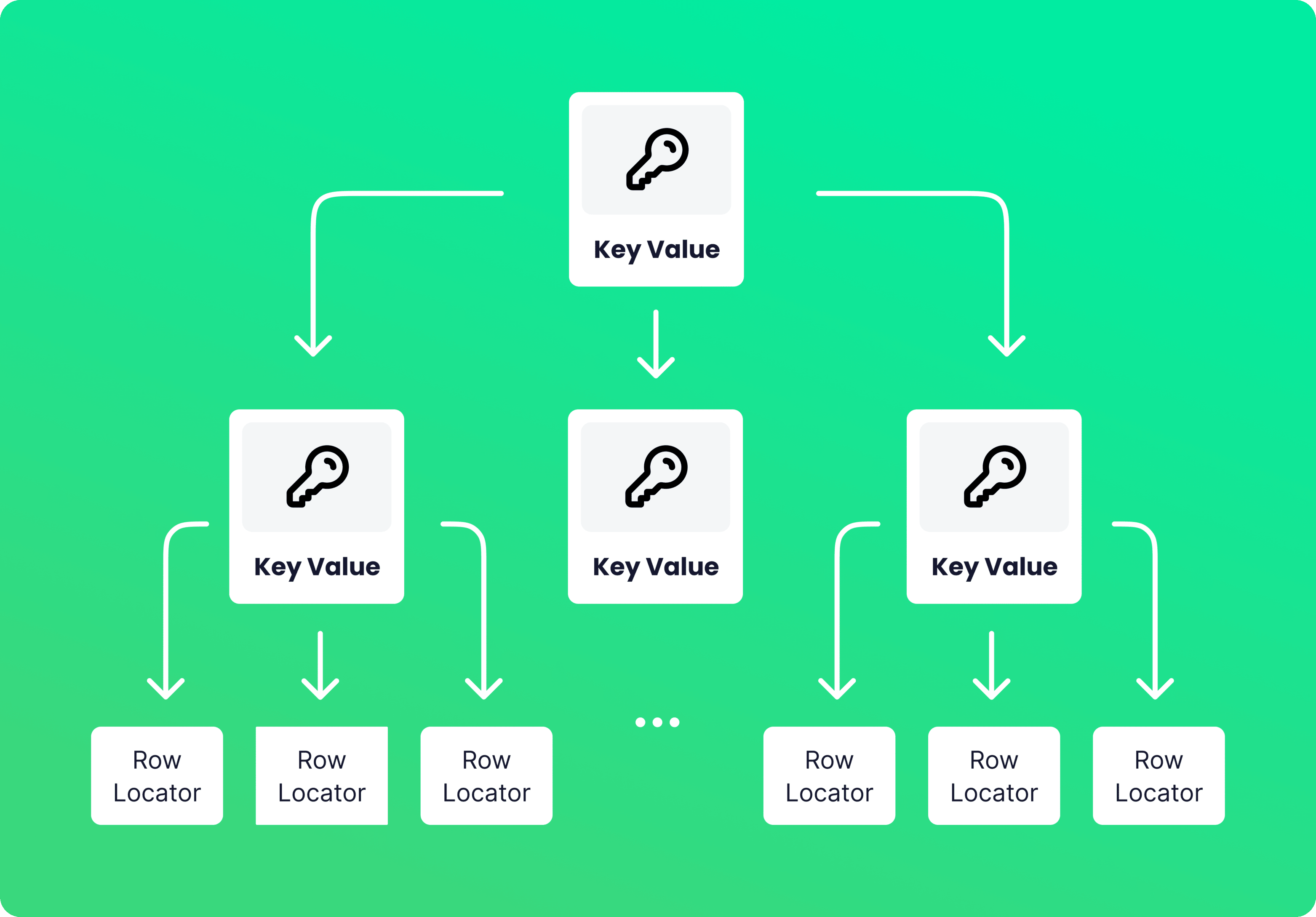
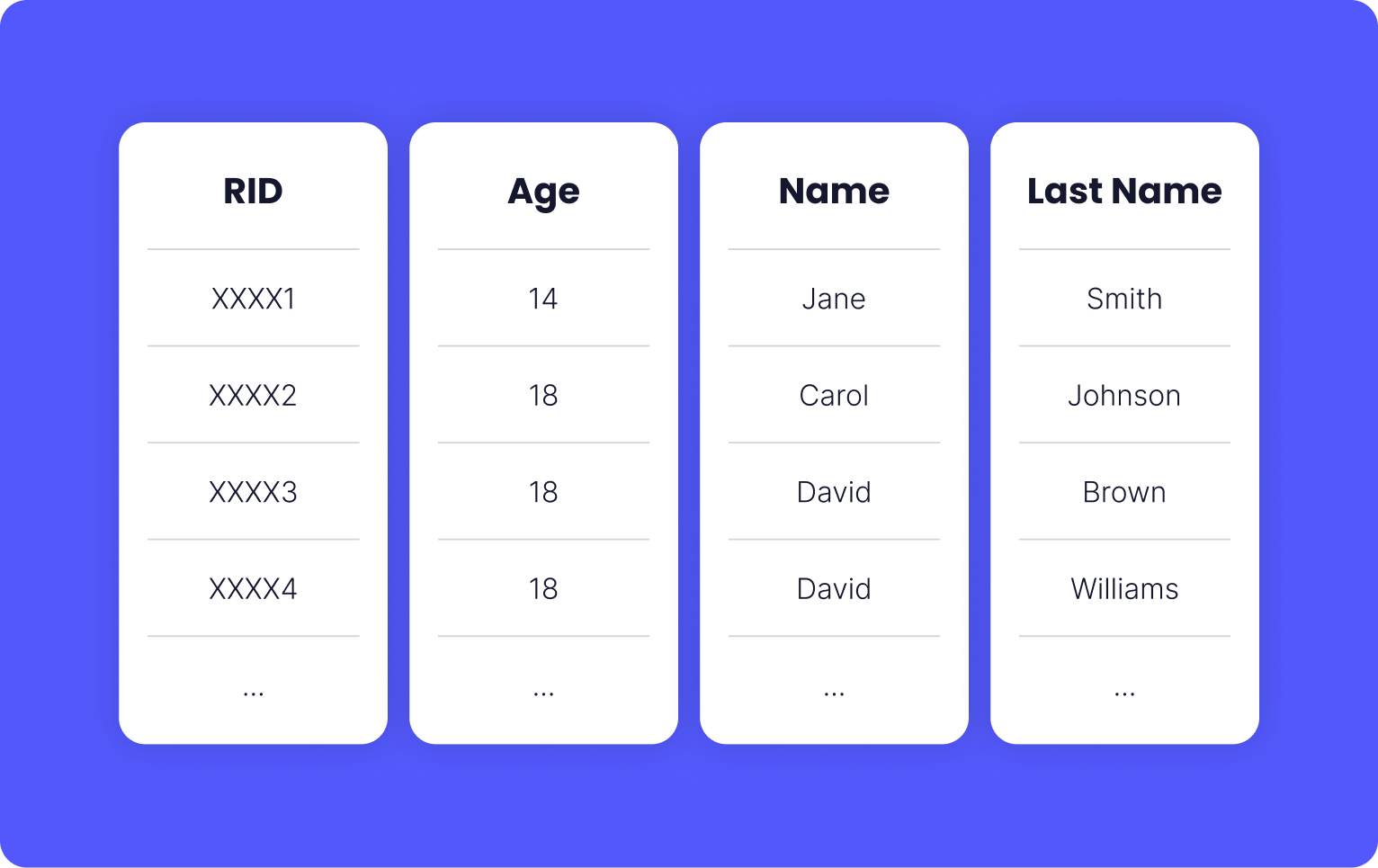
This is what one Row Locator looks like. The Row Locator is at first ordered by age, then by name, and at last, by lastname. This is why the order of columns on which you are building a non-clustered index matters.
4. How are indexes useful to reduce the Read time?
The time the database engine takes to run a query to retrieve data for it (Read query), is called the Read execution time. It is one of the most important factors of a good database-required application. Indexes are data structures that we build based on one or more columns of a table so that we decrease the Read query execution time. As mentioned before, indexes help us not need to scan the whole table to find the data and only scan a portion of it.
5. How many indexes can we create?
We can build only one clustered index per table. Since the rows can be sorted in only one order based on the column (columns) that the clustered index is built on. We can build as many non-clustered indexes per table as needed. Please pay attention that Indexes can be built for either tables or views.
6. If indexes decrease the Read time, why not create an index per column?
The reason is that when a table has many indexes built for its columns, the Write time increases. Whenever there is a Write operation to the database, the RDBMS has to modify all the indexes so that the new Write operation is written to and modify all of them as well.
7. Can creating an index on one or more columns necessarily decrease the Read time?
No, there are certain scenarios that not only indexing cannot help, but also it can increase the Read time. The things we put in WHERE clause can play a significant role in determining how well we are using the full capacity of the indexes. We must know the query in advance to be able to build an appropriate index.
8. Some examples for which creating an index is not useful for the performance.
- Inequality operator in WHERE clause. For example, assume we have many users whose age is greater than 10, therefore the RDBMS needs to scan the entire table or a significant portion of it to find the rows meeting the condition, and practically, it makes the index useless or less useful.
SELECT *
FROM app_user
WHERE age > 10;- Using functions at the WHERE clause can make RDBMS ignore using indexes. It is recommended that we do not use the functions in the WHERE clause. In the query below, the database has to check every age from every row to find which age, when raised to the square power, is less than 89.
SELECT age
FROM app_user
WHERE SQRT(age) < 89;- Column order matters in the WHERE clause. Assume you have created a multi-column index on the columns, C1, C2, and C3. If you want the database to use the full capacity of this index, your query should look like this.
SELECT c1, c2, c3
FROM table;-
When the number of rows in the table is not that high (not millions of millions), using an index is not necessary at all. It is possible that even if you have created an index on a small table, RDMS ignores the index and uses the Full Table Scan.
-
When the number of Writes to the database is so much more than the Reads, we better not create an index. As mentioned before, writing to an index can be a time-consuming process as the B-tree (or B+ tree) may have to be rebalanced every time we insert or update a row.
In conclusion, we talked about 2 of the most important topics that a Senior Backend/Full-stack Engineer must know when it comes to RDBMS.