We have been experimenting with AI coding tools almost since the beginning. Back in the early GitHub Copilot days, we were already testing what this new generation of developer tooling could realistically do inside a real production system, our platform that we started working on roughly seven years ago. At the time, honestly, we were not that impressed.
Copilot mostly felt like autocomplete on steroids. It was occasionally useful for boilerplate code and repetitive tasks, but it did not fundamentally change how experienced engineers worked. The gap between the online hype and the day-to-day reality was still very large. We kept experimenting anyway.
A long stretch of not-quite-there
Over the next couple of years we tried most of what came out. Cursor for a while. Never stuck with us. We gave Copilot licenses to everyone, then rolled out ChatGPT licenses around. Tried many other things too. We ended up running a stack of specialized tools for specialized jobs: Unblocked to explain unfamiliar parts of the system, CodeRabbit for a first-pass code review, Copilot and later JetBrains Junie for code generation. ChatGPT for everything in between. We were trying agentic workflows earlier than many teams around us did.
And for a long time, agentic coding still did not feel right for us.
The demos looked better than the actual experience. Agents lost context, made questionable architectural calls, introduced subtle bugs, needed constant babysitting to stay aligned with the original intent. Plenty of times, re-prompting took longer than just fixing the thing yourself. It felt that AI was like an overconfident intern: fast, helpful, but you had to watch it constantly. That was true. For a long stretch, it stayed true.
This is the part I want to underline before going further. We did not give up. We kept trying things we had already written off. And the lesson from the last six months is one I'll be carrying into every future judgment call: things that did not work six months ago can work exceptionally well now. Settling on "we tried it, it doesn't work" is the most expensive mistake you can make in a field moving this fast.
Things that did not work six months ago can work exceptionally well now. Settling on "we tried it, it doesn't work" is the most expensive mistake you can make in a field moving this fast.
Then something changed
About six months ago, something changed.
We had already experimented with Claude Code earlier, but starting around Opus 4.5, the overall experience suddenly crossed a threshold. The things that did not work before started to work. Not "slightly better." Differently. The agentic workflows we had given up on six months earlier started behaving like a useful colleague instead of an intern who needed constant supervision.
The skeptics on the team did not turn around because I made them, and we had several, including some of our most senior engineers. They turned around because they saw how they could benefit from it. They watched their peers ship work they couldn't have shipped that fast. They saw how quickly they could understand parts of the product they had never worked in before. And how quickly they could move when fixing things, or implementing something new. That pattern repeated across the team.
Today, agentic flows are our default. We still write some code manually, but only when it makes more sense than having agents do it on their own, because sometimes it's faster to just type the change than re-prompt for it. We still do manual code review after the automated one, and we have started using Codex, Copilot and Gemini alongside CodeRabbit here. We have not made up our final mind which one is best, so we keep experimenting. We are more deliberate about that review than we used to be, not less. Reviewers are doing more work, not less, because we can now generate code faster than some can fully understand it.
And it seems we are doing better these days after all of these changes.
The numbers behind the feeling
I have always been passionate about metrics, and some time ago we implemented Stanford-backed models to measure the output of our engineering team (that setup is probably worth a separate post). It has helped us see the actual results of changes we made internally, from process work to AI adoption to the shifts in how we work along the way.
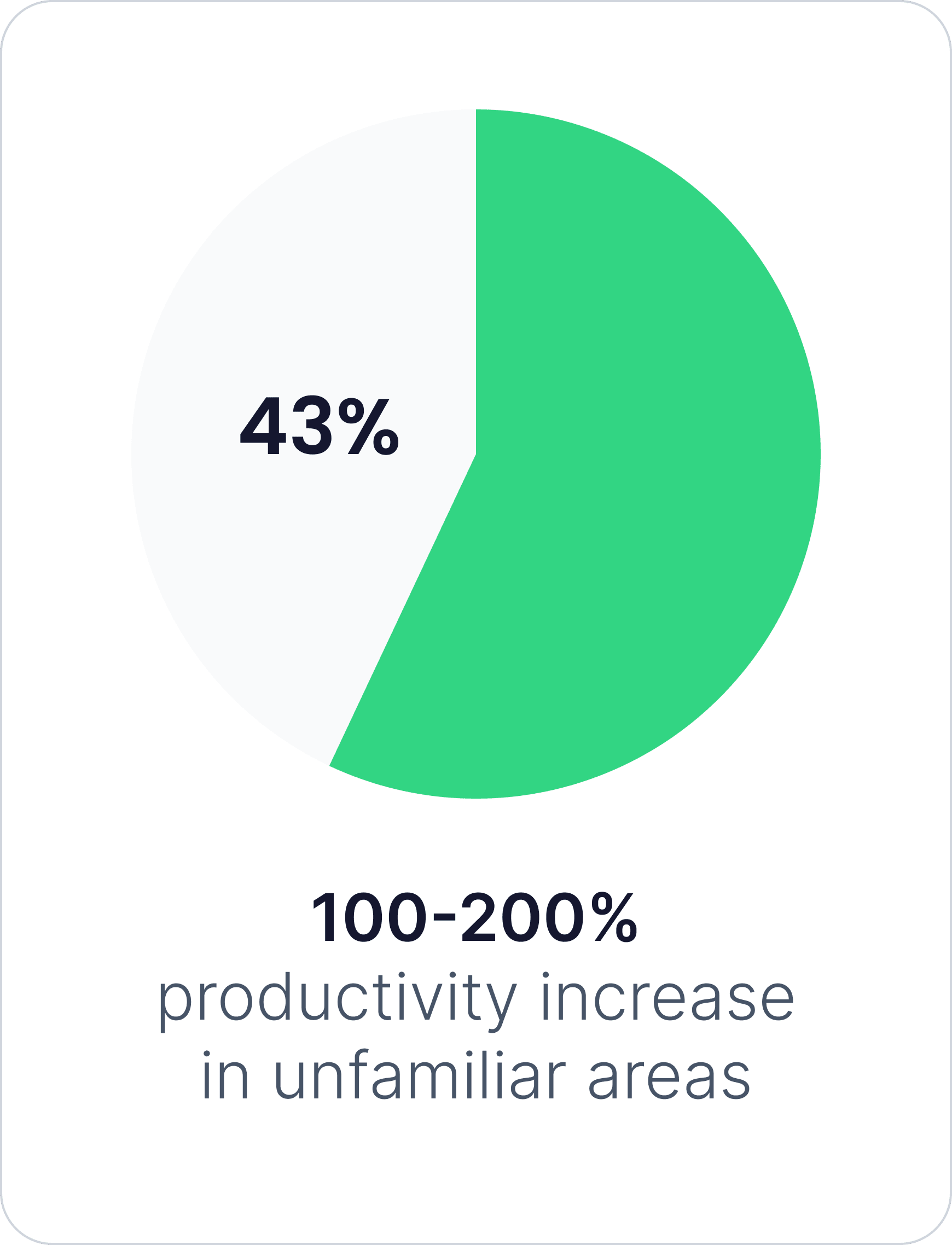
We started with an experiment. We asked our engineers how much better they felt we were doing these days, and then we compared their answers against the numbers. The largest reported gains came from working in unfamiliar territory, where roughly 43 percent of the team estimated a 100-200 percent productivity gain. In familiar areas the gains were smaller but still real. The two concerns that came up repeatedly were overreliance on the agent and the time spent validating output whose quality remains inconsistent. Both are real, and both are why we have not removed human review from the loop. If anything, we have made reviews more deliberate. |
|
Then we looked at what the platform itself was telling us. Output rose modestly during our first shift toward Copilot, grew more meaningfully through the next phase as we adopted more AI tooling, and jumped again once we moved toward agentic workflows. Alongside output, we were watching the quality score the whole time, and quality held steady across all “eras”, with a noticeable improvement once we moved to agentic workflows. That last bit matters to us, because the speed only counts if the quality holds.
Added productivity gains per era (team average): +21% Copilot era · +81% ChatGPT Team Plan era · +92% Claude Code era (Jan-May 2026). Combined, an increase of 320% since April 2023. Output units = standardized measures of software engineering output, estimated by a Stanford ML model trained to replicate expert evaluation of code changes. Read more: https://softwareengineeringproductivity.stanford.edu/
It was never just the tools
It would be misleading to credit AI alone for the gains. Over the years, alongside the adoption of new tools, we made huge changes in how we operate. We introduced communities of practice and hackathons. We made a big jump in test coverage. We rebuilt the whole release process and moved to mission-based ways of working. We also raised the bar in our hiring process and did some team restructuring.
What does this say to me? The tools are not the variable that matters anymore. They are commodity-adjacent and the gap between them is closing fast. What matters is the operating model around them. AI amplifies the operating model you already have. Strong engineering practices become a lot more effective. Weak ones become a lot more dangerous.
AI amplifies the operating model you already have. Strong engineering practices become a lot more effective. Weak ones become a lot more dangerous.
Over the past two years we rebuilt a lot of how the Engineering department works, in ways that compound with AI. Without that work, I do not think we would be looking at the same numbers.
What comes next
We are not stopping. We do not settle for what we have. We are constantly trying to improve how we operate. We are sharpening our set of used skills right now, figuring out which specializations to invest in and which ones to drop. Next up is mastering multi-agent orchestration. Opus 4.8, which just came out with its ultracode effort, is definitely going to help here. We will keep our guardrails on, and we will see if some of them need to change too.
If there is one thing I'd leave another engineering leader with, it is this. The tools will keep moving. The operating model is the part you control, and it is where the real compounding happens. Get that part right and the tools take care of themselves. And whatever you tried six months ago and put aside? Try it again.
AI tools we're actually using
Usage varies across the team, but Claude Code has been our main tool in recent months. Monthly spend sits at around €100 per software engineer.
The current stack:
Claude Code
Codex
Copilot
Gemini
CodeRabbit
Junie