"Proxify really got us a couple of amazing candidates who could immediately start doing productive work. This was crucial in clearing up our schedule and meeting our goals for the year."
Det største udviklernetværk i Europa
Stop med at spilde tid og penge på dårlige ansættelser og fokuser på at opbygge gode produkter. Vi matcher dig med de 1% bedste ETL freelanceudviklere, konsulenter, ingeniører, programmører og eksperter på få dage, ikke måneder.
ISO 27001
Certificeret

Betroet af 2.500 globale virksomheder
Hvis du ønsker at ansætte ETL-udviklere til dit næste projekt, behøver du ikke lede længere end Proxify. Proxify er et svensk-baseret firma grundlagt i 2018, der specialiserer sig i at matche virksomheder med højt kvalificerede fjernudviklere og andre teknologispecialister. Med et globalt netværk af topklasse, godkendte fagfolk sikrer Proxify, at kun de bedste talenter er tilgængelige for at imødekomme dine specifikke behov.
Hos Proxify forstår vi vigtigheden af kvalitet, når det kommer til at ansætte ETL-udviklere. Derfor bruger vi en stringent udvælgelsesproces, der kun accepterer cirka 1% af ansøgerne, for at sikre, at du får det absolut bedste. Vores service er bygget til at være hurtig, fleksibel og global, hvilket betyder mindre administrativ byrde for dig og hurtig opskalering af dine teknologiteams.
Uanset om du er en startup, der ønsker at bygge en hjemmeside fra bunden, eller en stor virksomhed med behov for løbende ETL-udviklingsunderstøttelse, har Proxify det talent, du har brug for. Vores ETL-udviklere har erfaring med en bred vifte af projekter, fra e-handelswebsteder til skræddersyede webapplikationer.
Når du ansætter ETL-udviklere gennem Proxify, kan du være sikker på, at du får førsteklasses talent, der er dedikeret til at levere høj kvalitetsarbejde til tiden og inden for budgettet. Vores udviklere er eksperter i ETL, samt andre programmeringssprog og frameworks, så du kan stole på, at dit projekt er i gode hænder.
Hvis du er interesseret i at ansætte ETL-udviklere gennem Proxify, skal du blot kontakte os og fortælle os dine specifikke krav. Uanset om du har brug for en enkelt udvikler eller et team af udviklere, kan vi hjælpe dig med at finde det rette talent til dit projekt. Med Proxify har det aldrig været nemmere at ansætte ETL-udviklere. Lad os tage besværet ud af at finde og ansætte førsteklasses talent, så du kan fokusere på det, du gør bedst.
Ansæt hurtigt med Proxify
Den ultimative ansættelsesguide: find og ansæt en top ETL-ekspert

Data Engineer
Ali er en talentfuld datatekniker med syv års erfaring. Han har arbejdet inden for forskellige fagområder, f.eks. forsikring, offentlige projekter og cloudsystemer.
Ekspert i

Data Engineer
Zakaria er en dygtig datatekniker med seks års erfaring inden for it, jernbaner og sundhedssektoren.
Ekspert i

Data Engineer
Felipe er dataingeniør med over 12 års erfaring inden for IT.
Ekspert i

Data Engineer
Ahmed har over 13 års omfattende erfaring som professionel inden for dataanalyse og Business Intelligence med speciale i dataanalyse og visualisering.
Ekspert i

Data Engineer
Gopal er dataingeniør med over otte års erfaring inden for regulerede sektorer som bilindustrien, teknologi og energi. Han udmærker sig i GCP, Azure, AWS og Snowflake med ekspertise inden for udvikling i hele livscyklussen, datamodellering, databasearkitektur og optimering af ydeevne.
Ekspert i

Data Engineer
Dean er dataingeniør med fem års kommerciel erfaring. Hans primære ekspertise ligger i at designe, opbygge og vedligeholde robuste datapipelines og infrastruktur.
Ekspert i

Data Engineer
Rihab er dataingeniør med over 7 års erfaring fra regulerede brancher som detailhandel, energi og fintech. Hun har stor teknisk ekspertise inden for Python og AWS og yderligere færdigheder inden for Scala, datatjenester og cloud-løsninger.
Ekspert i

BI-udvikler
Cristian er en erfaren BI-udvikler med over 20 års erfaring i at levere pålidelige, gennemgående rapporterings- og analyseløsninger. Hans tekniske værktøjskasse omfatter Power BI, SQL, SSIS og Azure Data Factory, og han har arbejdet meget inden for bank-, medie- og SaaS-sektoren.
Ekspert i
Data Engineer
Ali er en talentfuld datatekniker med syv års erfaring. Han har arbejdet inden for forskellige fagområder, f.eks. forsikring, offentlige projekter og cloudsystemer.
Ekspert i
Den ultimative ansættelsesguide: find og ansæt en top ETL-ekspert
Med en kombination af AI-teknologi og vores teams ekspertise leverer vi nøje udvalgte talenter på få dage.
Kickstart processen i tre enkle trin.
1

Book et 25-minutters møde, hvor du fortæller om dine behov, så matcher vi dig med velegnede kandidater.
2

Efter cirka to dage modtager du en liste med nøje udvalgte tilgængelige specialister, som du kan booke en samtale med.
3

Integrer dine nye teammedlemmer på maks. to uger. Vi tager os af HR og administration, så du ikke taber momentum.
Ansæt førsteklasses, kontrolleret talent. Hurtigt.

"Proxify really got us a couple of amazing candidates who could immediately start doing productive work. This was crucial in clearing up our schedule and meeting our goals for the year."
Proxify made hiring developers easy
The technical screening is excellent and saved our organisation a lot of work. They are also quick to reply and fun to work with.

Our Client Manager, Seah, is awesome
We found quality talent for our needs. The developers are knowledgeable and offer good insights.

Du slipper for CV-bunken. Vi har shortlistet de 1% bedste softwareingeniører i verden med ekspertise i over 1.000 teknologier og en gennemsnitlig erfaring på otte år. De er omhyggeligt screenet og kan starte med det samme."
Vi har en særdeles grundig screeningsproces. Proxify modtager over 20.000 ansøgninger om måneden fra udviklere, der ønsker at blive en del af vores netværk, men kun 2-3 % kommer gennem nåleøjet. Vi anvender et avanceret system til ansøgersporing, der vurderer erfaring, teknologi, prisniveau, geografisk placering og sprogfærdigheder.
Kandidaterne har en indledende samtale med en af vores rekrutteringsspecialister. Her får vi et billede af deres engelskkundskaber, bløde færdigheder, tekniske kompetencer, motivation, prisforventninger og tilgængelighed. Derudover afstemmer vi vores forventninger i henhold til efterspørgslen på deres færdigheder.
Næste trin er en programmeringstest, hvor kandidaten løser opgaver på tid. Opgaverne afspejler virkelige programmeringsopgaver, så vi kan teste deres evne til at løse problemer hurtigt og effektivt.
De bedste kandidater inviteres til en teknisk samtale. Her løser de programmeringsopgaver i realtid med vores erfarne ingeniører, hvor vi vurderer deres analytiske evner, tekniske kompetencer og problemløsningsevner i pressede situationer.
Når kandidaten har klaret sig imponerende godt i alle de foregående trin, bliver vedkommende inviteret til at blive medlem af Proxify-netværket.

"Qualität steht im Mittelpunkt unserer Arbeit. Unser umfassender Bewertungsprozess stellt sicher, dass nur die besten 1% der Entwickler dem Proxify Netzwerk beitreten, sodass unsere Kunden immer die besten Talente zur Verfügung haben."
Stoyan Merdzhanov
VP Assessment

Petar Stojanovski
Kundeingeniør
De sætter sig grundigt ind i dine tekniske udfordringer. Du får højt kvalificerede fagfolk, der hurtigt hjælper dig med at løse de vanskeligste udfordringer i din køreplan.

Teodor Månsson
Kundechef Nordics
Din langsigtede partner, der tilbyder personlig support i onboarding, HR og administration til at administrere dine Proxify udviklere.
Fremragende personlig service, der er skræddersyet fra start til slut – fordi du fortjener det.
ETL-udviklere bygger de pipelines, der flytter og omdanner rådata til brugbare formater til business intelligence, analyse og maskinlæring. Denne guide gennemgår alt, hvad du skal vide for at ansætte de bedste ETL-talenter, som vil hjælpe din organisation med at udnytte data effektivt.
ETL-udvikling er kernen i data engineering. Det indebærer at udtrække data fra forskellige kilder, omdanne dem til at opfylde forretningsbehov og indlæse dem i en lagringsløsning som et datalager eller en datasø.
Dagens ETL-udviklere arbejder med værktøjer som Apache Airflow, Talend, Informatica, Azure Data Factory og dbt (data build tool). De koder ofte i SQL, Python eller Java og bruger i stigende grad cloud-baserede tjenester fra AWS, Azure og Google Cloud.
En erfaren ETL-udvikler sikrer ikke kun, at data flyttes pålideligt, men også at de er rene, optimerede og klar til downstream-brug som f.eks. dashboards, rapportering og prædiktiv modellering.
Mens ETL (Extract, Transform, Load) og ELT (Extract, Load, Transform) tjener samme formål i dataintegration, er rækkefølgen af operationer og ideelle brugsscenarier meget forskellige. I traditionelle ETL-workflows transformeres data, før de indlæses i destinationssystemet - ideelt til lokale miljøer, og når transformationerne er komplekse eller følsomme.
ELT vender derimod op og ned på denne rækkefølge ved først at indlæse rådata i et målsystem - normalt et moderne cloud-datalager som Snowflake, BigQuery eller Redshift- og derefter transformere dem på stedet.
Denne tilgang udnytter cloud-platformenes skalerbare computerkraft til at håndtere store datasæt mere effektivt og forenkler pipeline-arkitekturen. Valget mellem ETL og ELT handler ofte om infrastruktur, datamængde og specifikke forretningskrav.
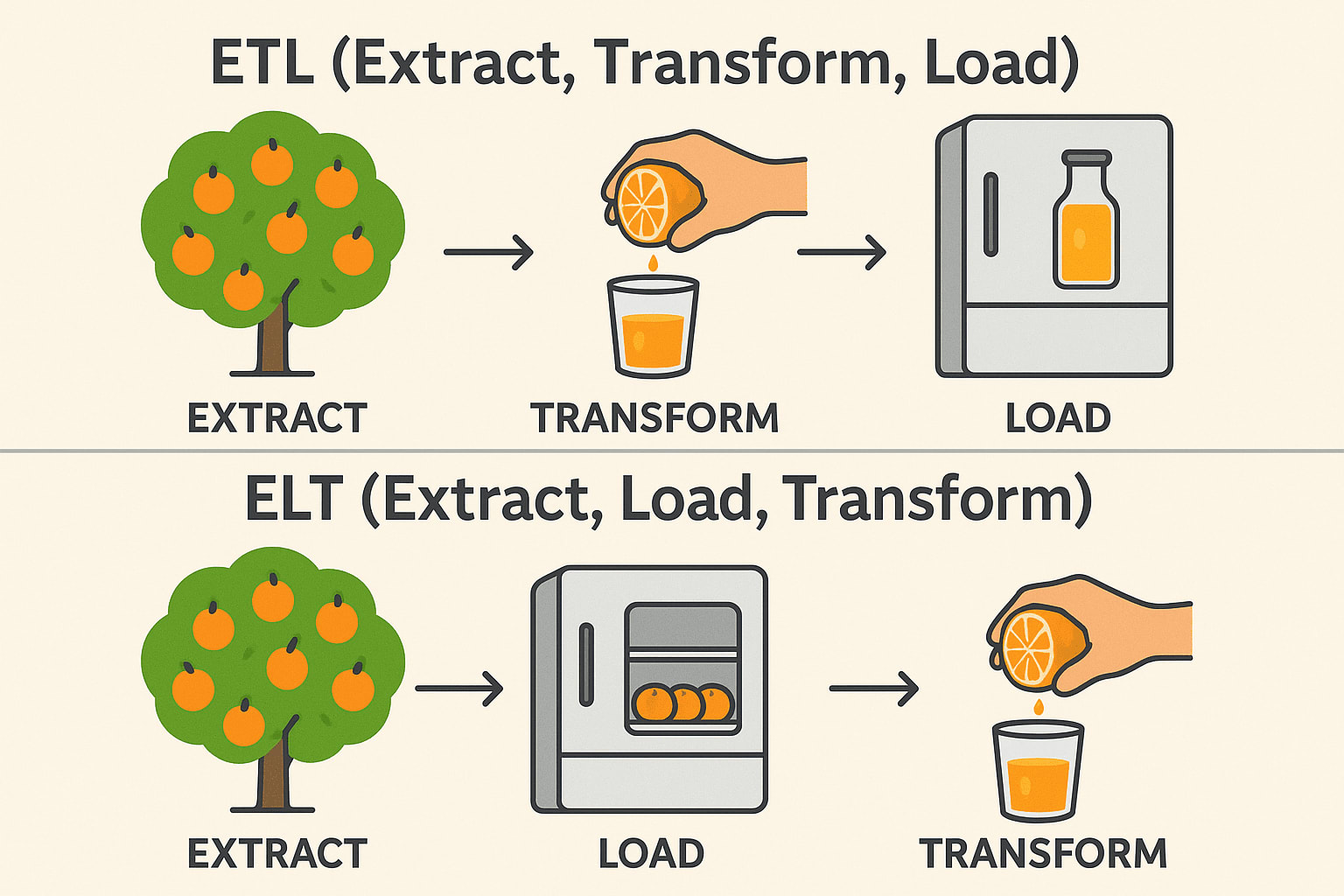
ETL (Udtræk → Transformér → Indlæs)
Extract: Pluk appelsiner fra træet (Indsaml rådata fra databaser, API'er eller filer). Transform: Pres dem til juice, før de gemmes (Rens, filtrer og formater dataene). Load: Opbevar den færdige juice i køleskabet (Gem strukturerede data i et datalager). Almindeligvis brugt i: Finans og sundhedspleje (data skal være rene før lagring).
ELT (Udtræk → Indlæs → Transformér)
Extract: Pluk appelsiner fra træet (Indsaml rådata fra databaser, API'er eller filer). Load: Opbevar de hele appelsiner i køleskabet først (Gem rådata i en datasø eller et cloud warehouse). Transform: Lav juice, når det er nødvendigt (bearbejd og analysér data senere). Almindeligvis brugt i: Big Data & Cloud (hurtigere, skalerbare transformationer). Teknisk stak: Snowflake, BigQuery, Databricks, AWS Redshift.
ETL-udviklere er uundværlige på tværs af flere brancher, herunder:
Uanset branche er virksomheder i stigende grad afhængige af nøjagtige, rettidige data, hvilket gør dygtige ETL-udviklere til et kritisk aktiv.
Når du ansætter en ETL-udvikler, skal du prioritere kandidater, der demonstrerer disse kernekompetencer:
En ETL-udvikler i topklasse skriver også klar, vedligeholdelsesvenlig kode og forstår principperne for datastyring og -sikkerhed.
Selv om det ikke er obligatorisk, kan følgende færdigheder adskille gode ETL-udviklere:
Disse ekstra funktioner kan give betydelig værdi, efterhånden som dine databehov bliver mere sofistikerede.
Her er nogle tankevækkende spørgsmål, der kan hjælpe dig med at vurdere kandidaterne:
1. Kan du beskrive den mest komplekse ETL-pipeline, du har bygget?
Se efter: Størrelse på datasæt, antal transformationer, fejlhåndteringsstrategier.
Eksempel på svar: Jeg byggede en pipeline, der udtrak brugerhændelsesdata fra flere apps, rensede og sammenføjede dataene, berigede dem med tredjepartsoplysninger og indlæste dem i Redshift. Jeg optimerede belastningen ved at partitionere data og brugte AWS Glue til orkestrering.
2. Hvordan sikrer du datakvalitet gennem hele ETL-processen?
Se efter: Datavalideringsmetoder, afstemningstrin, fejllogning.
Eksempel på svar: Jeg implementerer kontrolpunkter på hvert trin, bruger dataprofileringsværktøjer, logger uregelmæssigheder automatisk og opsætter alarmer, når tærsklerne overskrides.
3. Hvordan ville du optimere et ETL-job, der kører for langsomt?
Se efter: Partitionering, parallel behandling, optimering af forespørgsler og hardwaretuning.
Eksempel på svar: Jeg starter med at analysere forespørgselsudførelsesplaner, refaktorerer derefter transformationer for effektivitet, introducerer inkrementelle belastninger og opskalerer om nødvendigt beregningsressourcer.
4. Hvordan håndterer du skemaændringer i kildedata?
Se efter: Strategier for tilpasningsevne og robusthed.
Eksempel på svar: Jeg bygger skemavalidering ind i pipelinen, bruger versionsstyring til skemaopdateringer og designer ETL-jobs til at tilpasse sig dynamisk eller fejle elegant med advarsler.
5. Hvad er din erfaring med cloud-baserede ETL-værktøjer?
Se efter: Praktisk erfaring snarere end blot teoretisk viden.
Eksempel på svar: Jeg har brugt AWS Glue og Azure Data Factory i stor udstrækning, designet serverløse pipelines og udnyttet native integrationer med storage- og compute-tjenester.
6. Hvordan ville du designe en ETL-proces til at håndtere både fulde belastninger og inkrementelle belastninger?
Eksempel på svar: Ved fuld indlæsning designer jeg ETL'en til at afkorte og genindlæse måltabellerne, hvilket er velegnet til små til mellemstore datasæt. Til inkrementelle indlæsninger implementerer jeg CDC-mekanismer (Change Data Capture), enten via tidsstempler, versionsnumre eller databasetriggere. For eksempel kan jeg i en PostgreSQL-opsætning udnytte logiske replikeringsslots til kun at trække de ændrede rækker siden den sidste synkronisering.
7. Hvilke skridt ville du tage for at fejlfinde en datapipeline, der fejler med jævne mellemrum?
Svareksempel: Først gennemgår jeg pipeline-logfilerne for at finde mønstre, f.eks. tidsbaserede fejl eller dataafvigelser. Derefter isolerer jeg den fejlbehæftede opgave - hvis det er et transformationstrin, kører jeg det igen med eksempeldata lokalt. Jeg sætter ofte retries op med eksponentiel backoff og alarmer via værktøjer som PagerDuty for at sikre en rettidig reaktion på fejl.
8. Kan du forklare forskellene mellem batchbehandling og realtidsbehandling, og hvornår du ville vælge den ene frem for den anden?
Eksempel på svar: Batchbehandling indebærer indsamling af data over tid og behandling af dem i bulk, hvilket er perfekt til rapporteringssystemer, der ikke har brug for indsigt i realtid, som f.eks. salgsrapporter ved dagens slutning. Realtidsbehandling ved hjælp af teknologier som Apache Kafka eller AWS Kinesis er afgørende for brugssager som afsløring af svindel eller anbefalingsmotorer, hvor millisekunder betyder noget.
9. Hvordan håndterer du afhængigheder mellem flere ETL-jobs?
Eksempel på svar: Jeg bruger orkestreringsværktøjer som Apache Airflow, hvor jeg definerer Directed Acyclic Graphs (DAGs) til at udtrykke jobafhængigheder. For eksempel kan en DAG specificere, at 'extract'-opgaven skal være færdig, før 'transform' begynder. Jeg bruger også Airflows sensormekanismer til at vente på eksterne udløsere eller tilgængelighed af upstream-data.
10. Hvordan vil du i et cloud-miljø sikre følsomme data under ETL-processen?
Svareksempel: Jeg krypterer data både i hvile og i transit ved hjælp af værktøjer som AWS KMS til krypteringsnøgler. Jeg håndhæver strenge IAM-politikker, der sikrer, at kun autoriserede ETL-jobs og -tjenester kan få adgang til følsomme data. I pipelines maskerer eller tokeniserer jeg følsomme felter som PII (personligt identificerbare oplysninger) og vedligeholder detaljerede revisionslogfiler for at overvåge adgang og brug.
At ansætte en ETL-udvikler handler om mere end bare at finde en person, der kan flytte data fra punkt A til punkt B. Det handler om at finde en professionel, der forstår nuancerne i datakvalitet, ydeevne og skiftende forretningsbehov. Vi leder efter kandidater med et stærkt teknisk fundament, praktisk erfaring med moderne værktøjer og en proaktiv tilgang til problemløsning. Ideelt set vil din nye ETL-udvikler ikke kun vedligeholde dine datastrømme, men også løbende forbedre dem og sikre, at din organisations data altid er pålidelige, skalerbare og klar til handling.
Ansætter en ETL-udviklere?
Håndplukkede ETL eksperter med dokumenterede resultater, betroet af globale virksomheder.
Vi arbejder udelukkende med top-tier professionelle. Vores skribenter og anmeldere er omhyggeligt verificerede brancheeksperter fra Proxify-netværket, som sikrer, at hvert indhold er præcist, relevant og baseret på dyb ekspertise.

Jerome Pillay
Business Intelligence-konsulent og dataingeniør
Jerome er en erfaren Business Intelligence-konsulent med dokumenteret erfaring fra managementkonsulentbranchen. Han har ekspertise inden for statistisk dataanalyse, databaser, datalagring, datavidenskab og business intelligence, og han udnytter sine færdigheder til at levere handlingsorienteret indsigt og drive datainformeret beslutningstagning. Jerome er en meget dygtig it-professionel og har en bachelorgrad i datalogi fra University of KwaZulu-Natal.