"Proxify really got us a couple of amazing candidates who could immediately start doing productive work. This was crucial in clearing up our schedule and meeting our goals for the year."
Europas største utviklernettverk
Ikke kast bort tid og penger på dårlige ETL-utviklere, men fokuser på å lage gode produkter. Vi matcher deg med de beste 1% av frilansutviklere, konsulenter, ingeniører, programmerere og eksperter innen få dager, ikke måneder.
ISO 27001-
sertifisert

Betrodd av over 2 500 globale virksomheter
Hvis du ønsker å ansette ETL-utviklere til ditt neste prosjekt, trenger du ikke lete lenger enn Proxify. Proxify er et svensk-basert selskap grunnlagt i 2018 som spesialiserer seg på å matche bedrifter med høyt kvalifiserte eksterne utviklere og andre teknologispesialister. Med et globalt nettverk av toppklasse, godkjente fagfolk sikrer Proxify at kun de beste talentene er tilgjengelige for å møte dine spesifikke behov.
Hos Proxify forstår vi viktigheten av kvalitet når det gjelder å ansette ETL-utviklere. Det er derfor vi bruker en streng utvelgelsesprosess, der vi kun aksepterer omtrent 1% av søkerne, for å sikre at du får det aller beste. Vår tjeneste er bygget for å være rask, fleksibel og global, noe som betyr mindre administrativ byrde for deg og rask oppskalering av dine teknologiteam.
Enten du er en oppstartsbedrift som ønsker å bygge et nettsted fra bunnen av eller et stort selskap som trenger løpende støtte for ETL-utvikling, har Proxify talentet du trenger. Våre ETL-utviklere har erfaring med et bredt spekter av prosjekter, fra e-handelsnettsteder til skreddersydde nettapplikasjoner.
Når du ansetter ETL-utviklere gjennom Proxify, kan du være trygg på at du får førsteklasses talent som er dedikert til å levere høykvalitetsarbeid til rett tid og innenfor budsjettet. Våre utviklere er eksperter på ETL, samt andre programmeringsspråk og rammeverk, så du kan stole på at prosjektet ditt er i gode hender.
Hvis du er interessert i å ansette ETL-utviklere gjennom Proxify, er det bare å ta kontakt med oss og fortelle oss om dine spesifikke krav. Enten du trenger én enkelt utvikler eller et team av utviklere, kan vi hjelpe deg med å finne rett talent for prosjektet ditt. Med Proxify har det aldri vært enklere å ansette ETL-utviklere. La oss ta bryet med å finne og ansette førsteklasses talent, slik at du kan fokusere på det du gjør best.
Ansett raskt med Proxify
Den ultimate ansettelsesguiden: finn og ansett en topp ETL ekspert

Data Engineer
Ali er en talentfull dataingeniør med syv års erfaring. Han jobbet innen ulike felt, som forsikring, statlige prosjekter og skysystemer.
Ekspert i

Data Engineer
Zakaria er en dyktig dataingeniør med seks års erfaring innen IT, jernbane og helsevesen.
Ekspert i

Data Engineer
Felipe er en dataingeniør med over 12 års erfaring innen IT.
Ekspert i

Data Engineer
Ahmed kan skilte med over 13 års omfattende erfaring som ansatt som fagperson innen dataanalyse og business intelligence, med spesialisering i dataanalyse og visualisering.
Ekspert i

Data Engineer
Gopal er en dataingeniør med over åtte års erfaring i regulerte sektorer som bilindustri, teknologi og energi. Han er enestående innen GCP, Azure, AWS og Snowflake, med ekspertise i full livssyklusutvikling, datamodellering, databasearkitektur og ytelsesoptimalisering.
Ekspert i

Data Engineer
Dean er en dataingeniør med fem års forretningsbakgrunn. Hans primære ekspertise ligger i å designe, bygge og vedlikeholde robuste datarørledninger og infrastruktur.
Ekspert i

Data Engineer
Rihab er en dataingeniør med over 7 års erfaring fra regulerte bransjer som detaljhandel, energi og fintech. Hun har sterk teknisk ekspertise innen Python og AWS, med ekstra ferdigheter i Scala, datatjenester og skyløsninger.
Ekspert i

BI-utvikler
Cristian er en erfaren BI-utvikler med over 20 års erfaring med å levere pålitelige, gjennomgående rapporterings- og analyseløsninger. Hans tekniske verktøy omfatter Power BI, SQL, SSIS og Azure Data Factory, og han har jobbet mye i bank-, medie- og SaaS-sektoren.
Ekspert i
Data Engineer
Ali er en talentfull dataingeniør med syv års erfaring. Han jobbet innen ulike felt, som forsikring, statlige prosjekter og skysystemer.
Ekspert i
Den ultimate ansettelsesguiden: finn og ansett en topp ETL ekspert
Med hjelp av det beste innen AI-teknologi og teamets ekspertise leverer vi håndplukkede talenter på bare noen få dager.
Kom i gang med bare tre enkle trinn.
1

Fortell om deg selv og hva du trenger i løpet av et 25-minutters møte, slik at vi kan matche deg med de perfekte kandidatene.
2

Etter gjennomsnittlig to dager mottar du flere håndplukkede, arbeidsklare spesialister, som du kan booke en samtale med.
3

Integrer de nye teammedlemmene dine om to uker eller mindre. Vi håndterer HR og administrasjon, slik at du ikke mister fremdrift.
Ansett førsteklasses talent, kvalitetssikret. Raskt.

"Proxify really got us a couple of amazing candidates who could immediately start doing productive work. This was crucial in clearing up our schedule and meeting our goals for the year."
Proxify made hiring developers easy
The technical screening is excellent and saved our organisation a lot of work. They are also quick to reply and fun to work with.

Our Client Manager, Seah, is awesome
We found quality talent for our needs. The developers are knowledgeable and offer good insights.

Hopp over søknadshaugen. Nettverket vårt representerer de beste 1% av programvareingeniører over hele verden, med mer enn 1 000 tekniske kompetanser, og med et gjennomsnitt på åtte års erfaring. Der alle er grundig utvalgt og umiddelbart tilgjengelig."
Utvelgelsesprosessen vår er en av de mest grundige i bransjen. Over 20 000 utviklere søker hver måned om å bli med i nettverket vårt, men bare rundt 2–3 % kommer gjennom nåløyet. Når en kandidat søker, blir de evaluert gjennom systemet vårt for sporing av søknader. Vi vurderer faktorer som antall års erfaring, teknologiløsninger, priser, plassering og ferdigheter i engelsk.
Kandidatene møter en av våre rekrutterere for et introduksjonsintervju. Her går vi i dybden på engelskkunnskapene de har, myke ferdigheter, tekniske evner, motivasjon, priser og tilgjengelighet. Vi vurderer også forholdet mellom tilbud og etterspørsel for deres spesifikke ferdighetssett, og tilpasser forventningene våre basert på hvor etterspurt ferdighetene deres er.
Deretter mottar kandidaten en vurdering. Denne testen fokuserer på virkelige kodeutfordringer og feilretting, med en tidsbegrensning, for å vurdere hvordan de presterer under press. Den er utformet for å gjenspeile den typen arbeid de kommer til å gjøre med kunder, og sikrer at de har den nødvendige ekspertisen.
Kandidater som består vurderingen går videre til et teknisk intervju. Dette intervjuet inkluderer live-koding-øvelser med senioringeniørene våre, der de får presentert problemer og må finne de beste løsningene på stedet. Det er et dypdykk i deres tekniske ferdigheter, problemløsningsevner og evne til å tenke gjennom komplekse spørsmål.
Når kandidaten imponerer i alle de foregående stegene, inviteres de til å bli med i Proxify-nettverket.

"Kvalitet er kjernen i det vi gjør. Vår grundige vurderingsprosess sikrer at kun de 1 % beste av utviklere blir med i Proxify-nettverket, slik at kundene våre alltid får tilgang til de beste tilgjengelige talentene."
Stoyan Merdzhanov
VP Assessment

Petar Stojanovski
Klientingeniør
Tar deg tid til å forstå dine tekniske utfordringer grundig. Med deres ekspertise får du de fagfolkene som passer best til oppgaven, og de er klare til å løse de tøffeste utfordringene du står overfor.

Teodor Månsson
Kundeansvarlig Nordics
Din langsiktige samarbeidspartner, som tilbyr personlig støtte under introduksjon, HR og administrasjon for å håndtere Proxify-utviklerne dine.
ETL-utviklere bygger pipelines som flytter og omdanner rådata til brukbare formater for business intelligence, analyse og maskinlæring. Denne veiledningen går gjennom alt du trenger å vite for å ansette de beste ETL-talentene som vil hjelpe organisasjonen din med å utnytte data effektivt.
ETL-utvikling er kjernen i datateknikk. Det innebærer å hente ut data fra ulike kilder, transformere dem slik at de oppfyller virksomhetens behov, og laste dem inn i en lagringsløsning som et datavarehus eller en datasjø.
Dagens ETL-utviklere jobber med verktøy som Apache Airflow, Talend, Informatica, Azure Data Factory og dbt (data build tool). De koder ofte i SQL, Python eller Java, og bruker i økende grad skybaserte tjenester fra AWS, Azure og Google Cloud.
En erfaren ETL-utvikler sørger ikke bare for at dataene flyttes på en pålitelig måte, men også for at de er rene, optimaliserte og klare for nedstrøms bruk, for eksempel dashbord, rapportering og prediktiv modellering.
Selv om ETL (Extract, Transform, Load) og ELT (Extract, Load, Transform) tjener lignende formål innen dataintegrasjon, er rekkefølgen på operasjonene og de ideelle brukstilfellene svært forskjellige. I tradisjonelle ETL-arbeidsflyter blir dataene transformert før de lastes inn i destinasjonssystemet - ideelt for lokale miljøer og når transformasjonene er komplekse eller sensitive.
ELT, derimot, snur om på denne rekkefølgen ved først å laste inn rådata i et målsystem - vanligvis et moderne datalager i skyen som Snowflake, BigQuery eller Redshift - og deretter transformere dem på stedet.
Denne tilnærmingen utnytter den skalerbare datakraften til skyplattformer for å håndtere store datasett mer effektivt og forenkle pipeline-arkitekturen. Valget mellom ETL og ELT handler ofte om infrastruktur, datavolum og spesifikke forretningskrav.
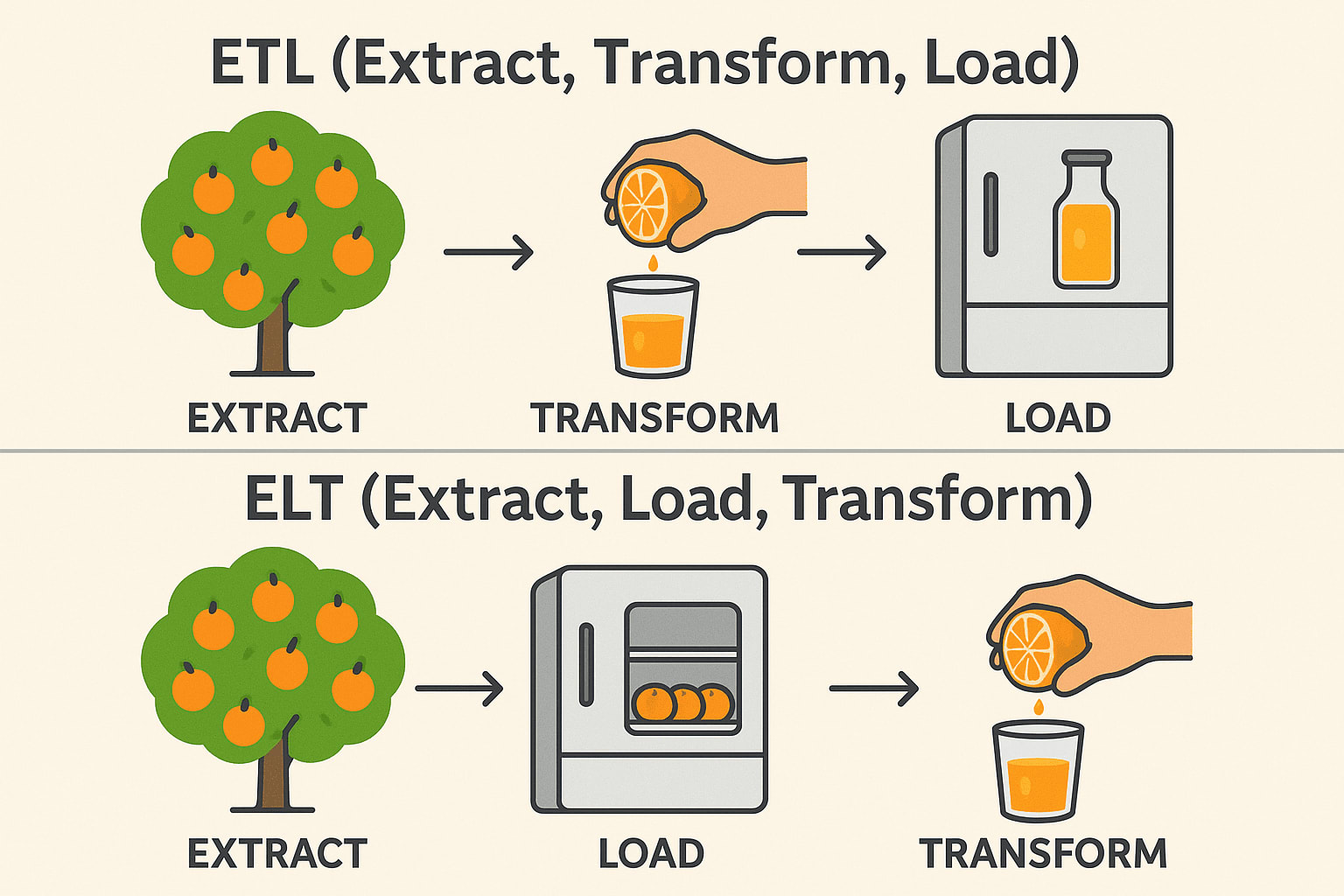
ETL (Extract → Transform → Load)
Extract: Plukk appelsiner fra treet (samle inn rådata fra databaser, API-er eller filer). Transformer: Press dem til juice før lagring (Rens, filtrer og formater dataene). Load: Oppbevar den ferdige juicen i kjøleskapet (Lagre strukturerte data i et datalager). Vanlig brukt i: Finans og helsevesen (data må være rene før lagring).
ELT (Extract → Load → Transform)
Extract: Plukk appelsiner fra treet (samle inn rådata fra databaser, API-er eller filer). Load: Lagre hele appelsiner i kjøleskapet først (Lagre rådata i en datasjø eller et skylager). Transform: Lag juice når det er nødvendig (behandle og analyser data senere). Vanlig brukt i: Big Data & Cloud (raskere, skalerbare transformasjoner). Teknisk stabel: Snowflake, BigQuery, Databricks, AWS Redshift.
ETL-utviklere er uunnværlige i mange bransjer, blant annet:
Uansett bransje er virksomheter i økende grad avhengige av nøyaktige og tidsriktige data, noe som gjør dyktige ETL-utviklere til en kritisk ressurs.
Når du ansetter en ETL-utvikler, bør du prioritere kandidater som kan vise til disse kjerneferdighetene:
En ETL-utvikler på toppnivå skriver også tydelig, vedlikeholdbar kode og forstår prinsippene for datastyring og sikkerhet.
Følgende ferdigheter er ikke obligatoriske, men de kan skille en god ETL-utvikler fra andre:
Disse tilleggsfunksjonene kan gi betydelig verdi etter hvert som databehovene dine blir mer sofistikerte.
Her er noen gjennomtenkte spørsmål som kan hjelpe deg med å vurdere kandidatene:
1. Kan du beskrive den mest komplekse ETL-pipelinen du har bygget?
Se etter: Størrelse på datasett, antall transformasjoner, feilhåndteringsstrategier.
Eksempel på svar: Jeg bygget en pipeline som hentet ut data om brukerhendelser fra flere apper, renset og sammenstilte dataene, beriket dem med tredjepartsinformasjon og lastet dem inn i Redshift. Jeg optimaliserte lastytelsen ved å partisjonere data og brukte AWS Glue for orkestrering.
2. Hvordan sikrer du datakvaliteten gjennom hele ETL-prosessen?
Se etter: Datavalideringsmetoder, avstemmingstrinn, feillogging.
Eksempel på svar: Jeg implementerer kontrollpunkter på hvert trinn, bruker dataprofileringsverktøy, logger avvik automatisk og setter opp varsler for terskelverdier som brytes.
3. Hvordan kan du optimalisere en ETL-jobb som går for sakte?
Se etter: Partisjonering, parallellprosessering, spørringsoptimalisering og maskinvaretuning.
Eksempel på svar: Jeg begynner med å analysere kjøringsplaner for spørringer, deretter refaktoriserer jeg transformasjoner for effektivitet, introduserer inkrementelle belastninger og skalerer om nødvendig opp beregningsressurser.
4. Hvordan håndterer du skjema-endringer i kildedata?
Se etter: Strategier for tilpasningsevne og robusthet.
Eksempel på svar: Jeg bygger inn skjemavalidering i pipelinen, bruker versjonskontroll for skjemauppdateringer og utformer ETL-jobber slik at de tilpasser seg dynamisk eller mislykkes på en elegant måte ved hjelp av varsler.
5. Hva er din erfaring med skybaserte ETL-verktøy?
Vi ser etter: Praktisk erfaring i stedet for bare teoretisk kunnskap.
Eksempel på svar: Jeg har brukt AWS Glue og Azure Data Factory i utstrakt grad, og har designet serverløse rørledninger og utnyttet integrerte integrasjoner med lagrings- og databehandlingstjenester.
6. Hvordan vil du utforme en ETL-prosess for å håndtere både full belastning og inkrementell belastning?
Eksempel på svar: For full innlasting utformer jeg ETL-en slik at den trunkerer og laster inn måltabellene på nytt, noe som passer for små til mellomstore datasett. For inkrementelle innlastinger implementerer jeg CDC-mekanismer (Change Data Capture), enten via tidsstempler, versjonsnumre eller databasetriggere. I et PostgreSQL-oppsett kan jeg for eksempel utnytte logiske replikasjonsspor for å hente bare de endrede radene siden forrige synkronisering.
7. Hva ville du gjort for å feilsøke en datapipeline som tidvis feiler?
Eksempel på svar: Først går jeg gjennom pipeline-loggene for å oppdage mønstre, for eksempel tidsbaserte feil eller dataavvik. Deretter isolerer jeg oppgaven som feiler - hvis det er et transformasjonstrinn, kjører jeg det på nytt med eksempeldata lokalt. Jeg setter ofte opp nye forsøk med eksponentiell backoff, og varsler via verktøy som PagerDuty for å sikre rask respons på feil.
8. Kan du forklare forskjellene mellom batchprosessering og sanntidsprosessering, og når du ville valgt det ene fremfor det andre?
Eksempel på svar: Batchbehandling innebærer å samle inn data over tid og behandle dem i bulk, noe som er perfekt for rapporteringssystemer som ikke trenger innsikt i sanntid, for eksempel salgsrapporter på slutten av dagen. Sanntidsbehandling ved hjelp av teknologier som Apache Kafka eller AWS Kinesis er avgjørende for brukstilfeller som svindeloppdagelse eller anbefalingsmotorer der millisekunder er avgjørende.
9. Hvordan håndterer du avhengigheter mellom flere ETL-jobber?
Eksempel på svar: Jeg bruker orkestreringsverktøy som Apache Airflow, der jeg definerer Directed Acyclic Graphs (DAGs) for å uttrykke jobbavhengigheter. En DAG kan for eksempel spesifisere at "extract"-oppgaven må være fullført før "transform" begynner. Jeg bruker også Airflows sensormekanismer for å vente på eksterne utløsere eller oppstrøms datatilgjengelighet.
10. Hvordan vil du sikre sensitive data under ETL-prosessen i et skymiljø?
Eksempel på svar: Jeg krypterer data både i hvile og i transitt, og bruker verktøy som AWS KMS for krypteringsnøkler. Jeg håndhever strenge IAM-policyer som sikrer at bare autoriserte ETL-jobber og -tjenester får tilgang til sensitive data. I pipelines maskerer eller tokeniserer jeg sensitive felt som PII (personlig identifiserbar informasjon) og vedlikeholder detaljerte revisjonslogger for å overvåke tilgang og bruk.
Å ansette en ETL-utvikler handler om mer enn bare å finne noen som kan flytte data fra punkt A til punkt B. Det handler om å finne en fagperson som forstår nyansene i datakvalitet, ytelse og skiftende forretningsbehov. Vi ser etter kandidater med et sterkt teknisk fundament, praktisk erfaring med moderne verktøy og en proaktiv tilnærming til problemløsning. Ideelt sett vil din nye ETL-utvikler ikke bare vedlikeholde datastrømmene dine, men også kontinuerlig forbedre dem, slik at organisasjonens data alltid er pålitelige, skalerbare og klare til bruk.
Ansetter en ETL-utviklere
Håndplukkede ETL eksperter med dokumentert erfaring, betrodd av globale selskaper.
Vi jobber utelukkende med toppnivå fagfolk. Våre forfattere og anmeldere er nøye vurderte bransjeeksperter fra Proxify-nettverket som sikrer at hvert innhold er presist, relevant og forankret i dyp ekspertise.

Jerome Pillay
Business Intelligence-konsulent og dataingeniør
Jerome er en erfaren Business Intelligence-konsulent med lang erfaring fra konsulentbransjen. Han har ekspertise innen statistisk dataanalyse, databaser, datalagring, datavitenskap og Business Intelligence, og utnytter ferdighetene sine til å levere innsikt som kan omsettes til handling og drive frem datainformert beslutningstaking. Jerome er en svært dyktig IT-profesjonell og har en bachelorgrad i informatikk fra University of KwaZulu-Natal.